Using AWS App Mesh to monitor and control your first containerized app
1日目としては3回目のWorkshopになります。Walk-Upで着いたのが30分前くらいだったのですが、すんなり入れました。Bellagioが会場だったのですが、セッションが少ない会場の一つだったためWalk-Upが増えにくいのかもしれません。賭けに出て良かった。
ちなみに列で待っていたときに、WeaveWorksのお兄さんらしき人がルービックキューブをくれました。 かわいい。

ざっくり言うとAppMesh導入したらどうなるの的な話でした。なんだか講師陣も優しく、声をかけてくれるしとても暖かかったように感じます。当たり前なんですがWorkshopでも会場や雰囲気によって温度感が全然違いますね。
あと、EKSのWorkshopのときにも思ったのですが、Workshopの会場はディスプレイ用意されていることが多いです。つなげるコード持ってくのがいいと思いました。自分はそもそもアメリカにも持ってきていないので断念しています。
Workshopの流れ
ECS, EKS, EC2 の順にそれぞれに対してAppMeshの導入を行いました。
実は最後にCloudMapも残っていたのですが、時間が余っているにも関わらず切られてしまいました。正直、CloudMapでサービスディスカバリしたかったです。自分でやるしか無いかと思ってはいますが、無料利用枠に入っているのか割と不安です。
EKSのときのWorkshopと同じでCloud9のセットアップから行っています。
資料はこちら
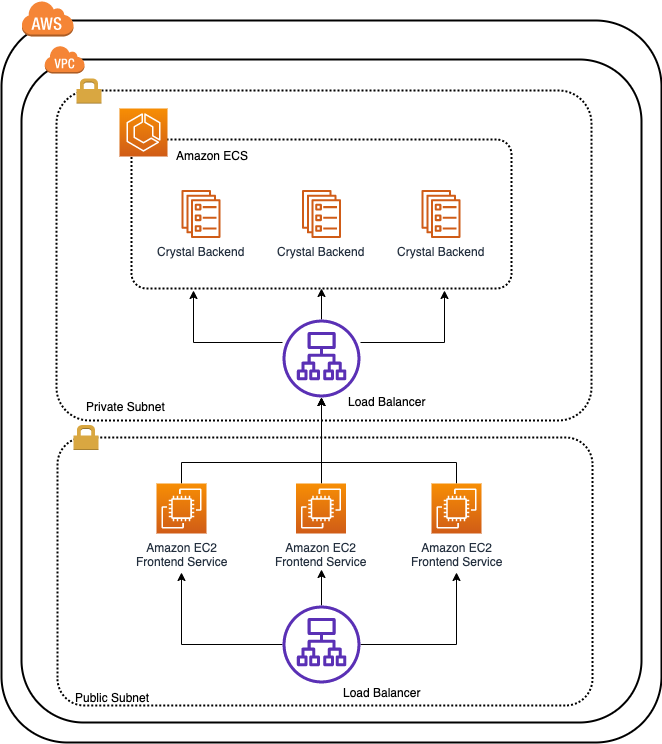
ベースラインのスタック作成
AppMeshを導入する前+Kubernetesリソース作成する前の構成はCloudFormationで作成していきます。フロントエンドのRubyはEC2のAutoScalingGroupで、バックエンドのCrystalがFargateとEKSクラスターという構成でデプロイされます。ASGとFargateの前には当然ながらロードバランサもいます。
自分がやったときには既にスタックは作成されていて実際に作成というのは行われませんでした。
NodeJsサービスのデプロイ
既に存在するEKSクラスターに対して、nodejsのサービスをデプロイしていきます。DeploymentとServiceをapplyするだけの簡単なお仕事です。その後に、フロントエンドのサービスからアクセスできるように、Route53にServiceリソースの向き先の入ったレコードを追加します。
フロントエンドのサービスのELBにアクセスすると、下記のような画面が表示され、3つのサービスが構成されていることが確認できます。

Crystal(Fargate)のメッシュ化
メッシュの作成
まずaws create-meshコマンドでメッシュを作成します。名前はappmesh-workshopとしています。「サービスメッシュはその内部に存在するサービス間のトラフィックの論理境界」としかその後の説明にないんですが、あまりピンと来ません。このコマンドでやっているのは結局コントロールプレーンの作成なのではと勝手に思っています(どうなんでしょう?)。
Virtual Serviceの作成
Virtual ServiceはVirtual Nodeによって提供されるrealなサービスの抽象化とのこと。…分からないです。Virtual NodeはASGやAmazon ECS Service, Kubernetesのdeploymentなど、特定のタスクグループへの論理ポインタを指す。これは分かりやすい。serviceDiscoveryの設定やlogging、listener(healthcheck)などの設定ができることからも非常に分かりやすい。そのVirtual Nodeを作成した後に、対応するVirtual Serviceを作っていく。Virtual Serviceに設定するのはVirtual Nodeの名前とサービス名にあたるFQDN。 今回はサービス名としてcrystal.appmeshworkshop.hosted.localを指定したので、Virtual Serviceの作成によってappmeshworkshop.hosted.localというprivate hosted zoneが作成され、Aレコードとしてcrystal.appmeshworkshop.hosted.localが登録されます。
Envoy Proxyの作成
AWSのAppMesh統合ではiptableを書き換えることでコンテナへの通信をインターセプトしているそう。Crystalのポート3000に通信がきたら、代わりにEnvoyがリッスンする15000ポートに流します。処理した後はEnvoyからCrystalへ通信を転送します。そのためレスポンスもEnvoyを通すことになります。
タスク定義にサイドカーのEnvoyの定義を追加してあげるだけはなく、proxyConfigurationというものも構成します。ここでTYPE: APPMESHを指定することで、指定したcontainerNameのコンテナに通信をインターセプトして流す形になります。
フロントエンドRubyのEC2にsshしてcrystal.appmeshworkshop.hosted.localに対して通信を行うと、Fargateの手前のinternal ALBに対して通信されます。curl -vで確認するとEnvoyから通信されていることが確認できるという流れになるようです。
NodeJS(EKS)のメッシュ化
メッシュ自体は既にappmesh-workshopという名前で作成されていますので、Vitrtual Serviceの作成とEnvoy Proxyの作成という形になるかと思います。
HELMでApp Mesh用のパッケージ導入
AppMesh用のCRDをapplyしていきます。リソースは下記リンクです。その後にhelmでeks/appmesh-controllerとeks/appmesh-injectというパッケージをインストールします。後者はmutating admission webhookらしいので、おそらくマニフェスト登録したときに、勝手にEnvoy Proxyを注入してくれるやつです。
Virtual Serviceの作成
Virtual NodeもVirtual ServiceもCRDで先程定義されたので、マニフェストをapplyして作成完了です。Virtual Serviceはパスルーティングも可能なんですね。小出しにそういう情報を出してくれるあたりが憎いです。kubectl label namespace appmesh-workshop-ns appmesh.k8s.aws/sidecarInjectorWebhook=enabledでnamespaceにlabelingすると、admission webhookが有効になるようです。podをdeleteするとenvoyがある状態で上がってきます。フロントエンドRubyにsshすると、Virtual Serviceリソースの.metadata.nameに記載したFQDNでアクセスできます。
Ruby(EC2)のメッシュ化
ECSのときと同じようにawsコマンドでVirtual NodeとVirtual Serviceを作成します。SSM Agentを使用して、Envoy Proxyを注入することで作業は完了です。
SSM Agentに関する知識が無かったので、ここは脳死でコピペしていました。
Loggingの有効化
Container InsightとX-rayの有効化を行いました。ECSはタスク定義のログ定義とX-Rayのサイドカーコンテナの注入、KubernetesはContainer InsightのデプロイとHelmでX-rayのパッケージをインストールすることで出来ました。
感想
AppMesh全然わからんという状態からちょっと分かる状態に持っていけるのは、Workshopのいいところですよね。CloudMapもやりたかった惜しい!



