幕張で開催されたAWS Summit2019にDay2から参加してきました!各セッションの感想を書いていきたいと思います。
セッションの他にもブース等回ろうと思っていましたが時間がなく、認定者ラウンジにちょっと立ち寄ったのみでした。ラウンジでは自撮りブースというものがあり、そこで自身の経歴もしくは資格を取って活きたこと、受験者に向けてのアドバイス等5つの設問から選んで、ビデオカメラに向けて話すとTシャツがもらえるとのことだったので、参加してもらってきました。
(背面のキャラクターかわいいけど誰なんだ…?)

英語力強くしたかったので、英語のセッションに関しては翻訳ではなくそのまま聞いています。
もしかしたら解釈違いなどあるかもしれません。
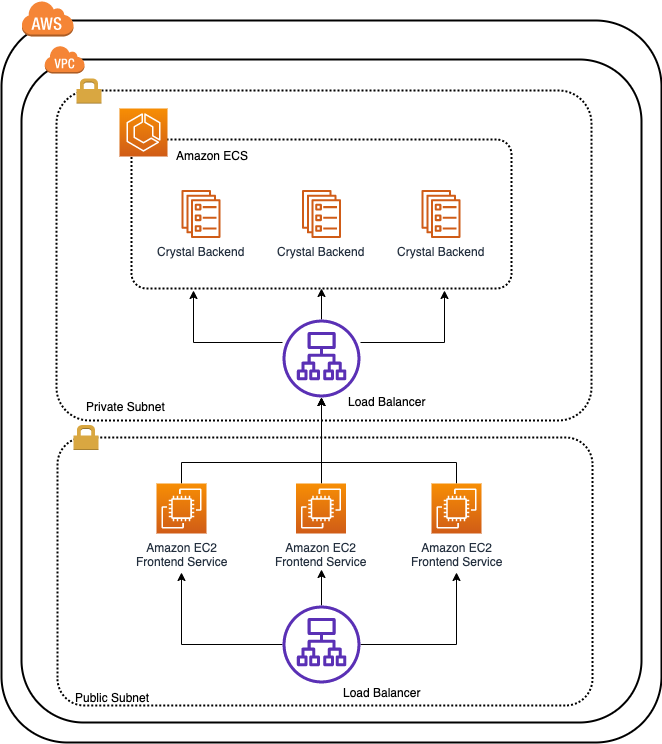
コンテナ化されたアプリケーションのAWSでの構築・運用指針
全体的に真新しい話はありませんでしたが、コンテナワークロードのメリットや近年の機能追加を再確認できるセッションだったかと思います。
Fargateの強み
インスタンスをManageする必要がなくなるため、Operationも非常にシンプルなり、ビジネスロジックに注力できる。
またSecurityに関してもAWS側で随時パッチを当てるので、その部分の対応コストもいらないし安全である。
Securityにも関わることですが、実行基盤のFirecrackerも同時に紹介されていました。
下記の点からAWSはFargateをもっと使ってもらいたいのかなと感じた
- Fargate利用者が伸びていることをスライドで紹介
- コンテナをテーマにしたセッションの中でServerlessを強く推していたこと
- 年末年始にFargateの価格が大幅に下がったことにも触れていた
CDKを是非使ってほしい
※ Developer Preview
十数行〜何百行のyamlを書かずともJS×CDKで書くことで、yamlよりかなり簡潔な記述でAWSのInfrastructureを構成することが可能。
対応言語としては「C#/ .NET、Java、JavaScript、Python、TypeScript」
裏ではCloudFormationが動いていてスタックとしてProvisioningされるようです。
下記の記事にはAWS FargateをTypescriptでProvisioningするサンプルコードがありますが、かなり簡潔に書けるようです。このサンプルだと600行超のコードが21行で記述できてます。
暗黙でセットしている値や作成しているリソースが多そうなのでそこは気をつけたいですね。
docs.aws.amazon.com
Elastic Container Services for Kubernetes
KubernetesとAWSの既存のサービスの統合にはかなり力を入れているとのことでした。 特にCNIプラグイン周り。
また、Maste NodeをAZ3箇所で冗長化を図っているのというのはびっくりしました。GCPはデフォルトだと1Zoneのみなので、AWSがマルチゾーンに展開していると思っていませんでした。
セッションの中でUpstreamであることを強調されていた印象です。Amazon AuroraのようにForkしてAWS独自の改修を加えているわけではないとのことで、ベンダーロックインの無い状態でKubernetesを使える+オープンソースコミュニティに寄り添っているという主張だったのでしょうか。嬉しいです。
ここ1年間でのLaunch
事例紹介
UberEatsなどの配信プロバイダと連携するためのプラットフォーム
ECSやSQSを組み合わせて100msecのレイテンシで20000order/secまで拡張が可能
aws.amazon.com
サーバーレスのメリットなどは既に分かっている前提で、では現在ある問題点に対してAWSはどうアプローチしているかという観点でのお話が多かったと思います。Lambdaを使う上で自分も問題だなと思う点はだいたい網羅されていたように感じます。
Lambda Layer × AWS Configの話はもうちょっと掘って理解したいと思います。
サーバーレスへの懸念
- 新しい開発者がLambdaに適合できるか
- SecurityやGovernanceはどのように担保するのか
- MonitoringやLoggingはどのように行えばいいのか
- Performanceはどうチューニングすればいいのか
FaaS開発の速度を爆速にしてくれる。
CloudFormationをServerless用に拡張したものテンプレートが構成要素の一つ。Serverless用のResourceTypeが用意されている。例えば、コードに紐付けるAPI Gatewayも同時に定義することができるApiリソースやDynamoDBのテーブルを定義できるSimpleTableなどが存在する。
非ServerlessリソースもSAMテンプレートには含めることができる。例えば併せて使うことが多いS3などは通常のCloudFormationの定義と同じように書ける。
SAMの構成要素の一つでコアな部分を担っているのがaws sam-cliです。
ログの追跡やローカルでの関数の呼び出しやAPI Gatewayの実行が可能になる。
ローカルで実行できるDynamoDBと併せて使うとなおよし。
Security & Governance
2つのPolicyを使い分けて権限を操作する
- 同期・非同期呼び出しのときはFunction Policy
- ストリーム呼び出しのときはExecution Role
SAMテンプレートにPolicyも記述できる。権限に関してもコードで管理できる。
Lambdaを外から見たときのGovernanceという観点では下記の2つ
- CloudTrail
- API呼び出しをCaptureする
- AWS Config
- AWS Config が AWS Lambda 関数のサポートを追加
ではコード自体のガバナンスをどうするか
- PipelineでCodeを自動チェックする
- レイヤーの作成を追跡可能にする
- レイヤーはイミュータブルで更新はバージョニングで行われる
- SAM テンプレートでレイヤを定義することができる
Monitoring/Logging/Trouble Shooting
ビルトインのMetricsも充実しているが、lambdaのsdkを使えば、putMetricDataでカスタムメトリクスも収集が可能。
"debug: in "という記述とともにログ出力するとinsightで見つけやすい。
Memory割当てを少なくすればするほど安くなるとは限らない。
Menory割当によってCPUの割当が変わるので、実行しているアプリケーションがCPUバインドなのかそうでないのか見極めてMemoryを割り当てるべき。
構成されているメモリの量に比例して CPU パワーが直線的に割り当てられます。1,792 MB では、関数は 1 つのフル vCPU (1 秒あたりのクレジットの 1 vCPU 秒) に相当
DeNA の QCT マネジメント IaaS 利用のベストプラクティス
オンプレからそのままクラウドに移行すると単純にコストが増加するという話は非常にうなずけるお話でした。クラウドに適合する形にしつつ、オンプレのナレッジが潤沢にある企業の場合はどのような戦略を取っていくのかというのが見られて勉強になりました。
オンプレから全面クラウド移行
オンプレでのナレッジがものすごく溜まっていてそれを活かそうとする構成にするために最適化させた構成にしているという印象でした。
基本は全てApp on EC2の構成。一番前段にALBを置いていて、それより後ろのレイヤではMyDNSを使ってServiceDiscoveryを行っているそうです。Route53のAutoNaming APIとかに乗っかってもいいのではと個人的には思いましたが、おそらくそれでは要件を満たせなかったのだと思います。
Scalingに関しても、ASGやCloudWatchを使わず自前で実装を行っていましたが、これも柔軟性を求めた結果なのだと思います。スクラッチで組み上げてしまうなんて、ものすごい技術力のある会社さんだなと思いました。
スポットインスタンスが強制Terminateされたときのハンドリングについてですが、リンクローカルアドレスを数秒間間隔で叩くDaemonを用意する。terminateのエンドポイントが200で帰ってきたら終了処理。
ログの扱いについてですが、終了直前のログが転送できないという課題を持っていたそうです。おそらくfluetndを使った高頻度での転送などは行っていなかったのだと思います。そのためEBSをインスタンスがTerminateされるタイミングで削除せず、そのまま残してバッチ処理で残っているログを転送するという形にしたそうです。
スポットインスタンスの大量Terminateが起こることがある。例えば、AmazonのCyber MondayやBlack Fridayでは顕著にその傾向が見られた。そのため、20プールの確保をするようにした。
プール=AZ × インスタンスタイプ × 世代。ファミリーを統一してタイプをバラバラにすることでアプリケーションの挙動差異を少なくしている。コア数が多いものが起動したときはIP数を増やして(ENIをアタッチして)その分多くリクエストをさばくようにする。
Serverless/AppSync によるモバイル開発の今
アプリ開発のバックエンド周りは疎い自分でも多くのメリットを享受できることが分かるセッションでした。
AppSync概要
AppSyncはManaged GraphQL Service
GraphQLはクライアントからQuery / Mutation / Subscription出来るようにするためのデータ言語。GraphQLのクエリではクライアント側がレスポンスの形式を指定。SubscriptionはMutationをトリガーとしてリアルタイムでのデータ更新を行う(Websocket通信)。Mutationはオフラインの状態で更新したら、復帰した段階でサーバ側と同期を取ってくれる。
AppSyncのデータソースはLambdaやDynamoDB、ElasticSearchなど…。
グノシースポーツでの事例。
各スポーツによって画面の仕様や欲しい情報などが異なることがあるため、クライアント側で定義できるGraphQLを採用。
導入手順
- スキーマ定義
- Resolver Mapping Templateの作成
- デフォルト値の定義やValidation, Format, データの変換などを行う
- 厳密には下記の2つ
- リクエストマッピングテンプレート
- レスポンスマッピングテンプレート
試合のスコアなどをリアルタイムに更新
- DynamoDBにUpdateが行われる
- DynamoDB streamでLambdaをキック
- LambdaからAppSyncにpublish
- AppSyncがアプリと同期する
新規開発時の悩みが解消
- 仕様書書くのだるい
- 必要なデータを選ぶのはアプリエンジニア
- UIの細かい改善がフロントだけで出来るようになる
Demo
amplifyを使ってSPA+AppMeshの構成でアプリケーションを作成していました。amplifyを知りませんでしたが、あそこまでシームレスにアプリが構築できてしまうのを見ると用途によってはゴリゴリ使えるような気がしますね。
amplify add apiでAWSリソースがProvisionされました。本当に簡単でした。びっくり。
DemoのPartに入られる前にこのPartが本当に怖いよとおっしゃっていたのがキュートで印象的でしたね。
Amazon Managed Blockchainの使いどころとソニー・ミュージック様における使用事例について
AWSが提供しているブロックチェーンのマネージドサービスの一つ。サポートしているアルゴリズムはHyperledger Fabricで、ethereumも近日サポート予定になっている。ブロックチェーンネットワークの作成・管理を行うことができる。
re:Inventで発表されていたものの、あまり具体的なユースケースが自分の中で分かっていなくてモヤモヤしていた部分のブロックチェーン関連サービス。
国内事例やQLDBとの使い分けを聞くことで、何かに使えないかと意識するきっかけになりました。
- QLDB
- Block chain partner
- Blockchainのsolutionを提供するAWS Partner Network
- AWS Blockchainテンプレート
- EtheriumとHyperledger Fabricに対応
- CloudFormationのテンプレート
よくいただく相談
- どうやってスケールさせるか
- ノードのスケーラビリティをお客様自身で設定
- スケール設定によってはリーズナブルにPoCが可能
構築フロー
鍵管理のベストプラクティス
コンプライアンス要件を厳しいケースにはKMSではなくCloudHSMを使用
他のネットワークから分離するためにVPCも併せて利用することで厳しい要件をクリアできる
またCloudHSMがサポートsecp256k1をサポート(ブロックチェーンの鍵は楕円曲線暗号で暗号化される必要がある?ため)
- 信頼された中央機関による台帳
- 分散機関によるトランザクション実行(Managed Blockchain)
ここが詳しい
ソニー・ミュージックの事例
音楽業界の課題という背景から、実際に使用されてみたTips、デモなどをして頂いたのですが、自分に音楽業界とブロックチェーンのどちらの知識も無くちゃんと内容追えなくなってしまいました。スライド公開されたらゆっくり理解したいと思います。
事業責任者も必見!AWS Well-Architected Frameworkのビジネスへの有効活用
既にスライドが公開されています。
CAという大きな会社で高品質のインフラを維持するためには、社内向けのWell-Architected Frameworkを作るというのが非常にプラスにつながっていくんだなと感じました。マルチクラウドで共通のチェックシートを作成する+項目を絞って75項目にするという作業は非常に難しかったのではないかと思います。特にプライベートクラウドもあるわけですし…。
また定期的なチェックというのは凄く良いよなと思いました。新機能のリリースなどで初期の頃に仕方なくイケてない形で構築したものなどを改善できるケースは多くありそうです。
事業責任者も必見! AWS Well-Architected Frameworkの ビジネスへの有効活用 / AWS Well-Architected Framework - Speaker Deck
こちらも既にスライドが公開されていました。
どうしてシングルテナントを選んだのか?namespaceで分けるのではなくクラスターごと分けるという意味です。自分の勤めている会社ではSREというポジションが無いのですが、SREが陥ってしまった状況とその問題点からそれを解決するための権限と業務の委譲、シングルテナントを選択するに至った動機が丁寧にストーリーに落とし込まれていて、とても知見でした。
移譲する上で品質の低下や移譲先の負荷を高めないと言う点での取り組みも勉強になりました。例えばクラスター作成用のeksclstという社内ツール作成している点などです。
AWSのマネージドサービスを活かした Kubernetes 運用とAmazon EKS によるクラスタのシングルテナント戦略について - Speaker Deck
まとめ
コンテナなど慣れ親しんでいるサービスからAppsyncやManaged Blockchainなどのあまり関わったことのないサービスまで多くの知見が得られました!
来年も行きたい!