記事一覧はこちら
背景/モチベーション
おれはBitbucket PipelineでARMコンテナをビルドしたいんだ! AWSのGravitonインスタンスを使っている会社さん多いのではないでしょうか。スポットインスタンスの価格が落ち着くまで結構かかったので、供給より需要の方が大きかったのではと睨んでいます。
必然的にARMアーキテクチャのコンテナビルドの必要性も高まります。 ただ、調べた限りだとBitbucket Pipelineにはその手立てがなさそうです。
dockerのexpermentalな機能を使えないという点があり、buildxも使えない状態だったので、諦めていたのですが、dockerのv20.10 からexperimentalが外れるということで、もしかしたらARMアーキテクチャのコンテナのビルドが出来るのかもと思い調べてみた次第です。 (正直、特権コンテナを動かせない時点で詰んでるなあとは思っているんですが…)
buildxとは
下記のようなコマンドでARMアーキテクチャをターゲットにビルドできます。
まず、ここで利用されている buildx コマンドについて明らかにしていきます。
$ docker buildx build --platform linux/amd64,linux/arm64 .
概要
buildx はBuildkitを用いてビルド機能を拡張するためのDocker CLIプラグインです。
Docker19.03から含まれるようになり、v20.10からexpermentalが外れています。
機能としては主に下記のものがあります。
docker buildと同じユーザーエクスペリエンス- コンテナドライバを使うことでBuildkitの全ての機能が利用可能
- 複数のビルダーインスタンスをサポート
- クロスプラットフォームのイメージビルド
buildx はドライバのコンセプトによって違う設定で実行できるようになっています。
現在は、Dockerデーモンにバンドルされている docker ドライバとDockerコンテナ内でBuildkitを自動的に起動する docker-container ドライバをサポートしているそう。
DockerデーモンにバンドルされているBuildkitライブラリが異なるストレージコンポーネントを利用しているようなので、docker ドライバではサポートされていない機能があります
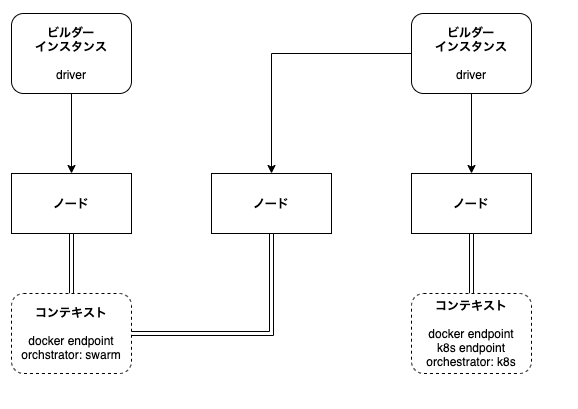
ビルダーインスタンスとは
Dockerコンテナのビルドを行う環境のこと。
デフォルトでは、ローカルの共有デーモンを利用する docker ドライバを利用します。
buildxでは、isolatedなビルダーインスタンスを作成することができます。 CIでの利用に適したスコープの限られた環境や異なるブロジェクト用にビルドを分離した環境として使用できる。リモートノードを使用することも可能。
docker buildx create コマンドで作成できる。リモートノードを作成するときには、 DOCKER_HOST もしくはリモートコンテキスト名を指定する。
ビルダーの切り替えは、 docker buildx use <name> を使う( kubetcl config use-context みたい )。
docker context のサブコマンドを利用して、リモートのDocker APIエンドポイントを管理できます(参考)
厳密には違うかもしれませんが、おおよそ関係性としては下記のような感じになります。
マルチプラットフォームビルド
Buildkitは複数のアーキテクチャをターゲットにしたビルドが機能します。
--platform フラグを使用して、ビルド対象のプラットフォームを指定できます。指定された、全てのアーキテクチャのイメージを含むマニフェストリストが作成されます。
QEMUエミュレーションを利用して異なるアーキテクチャにビルドする方法に関しては、次節で見ていきたいと思います。
例えば、 linux/amd64 と linux/arm64 のアーキテクチャのネイティブノードを用意してビルドするのであれば、下記のようなコマンドを発行すれば良いはずです(試せてない)。
# それぞれのContextを作成する $ docker context create node-amd64 \ --default-stack-orchestrator=swarm \ --docker host="host=ssh://<username>@amd64server" $ docker context create node-arm64 \ --default-stack-orchestrator=swarm \ --docker host="host=ssh://<username>@arm64server" # mybuild というビルダーインスタンスを作成 $ docker buildx create --use --name mybuild node-amd64 mybuild $ docker buildx create --append --name mybuild node-arm64 $ docker buildx build --platform linux/amd64,linux/arm64 .
QEMU で異なるアーキテクチャのコンテナイメージをビルドする
QEMUエミュレーションをbuildxから簡単に利用できますが、どのような形になっているのかは確認しておきたいと思います。
QEMUとは
ArchLinuxのWiki と QEMUの公式ページ を参考にしました。
QEMU(きゅーえみゅ)はOSSのマシンエミュレータ、バーチャライザーです。マシンエミュレーターとして使用すると別のアーキテクチャ用にビルドされたOSまたはアプリケーションを動かすことができます。
QEMUのエミュレーションモードは、フルシステムとユーザースペースの2つに分けられます。 フルシステムは周辺機器を含めて1つ以上のプロセッサをエミュレートします。ターゲットのCPUアーキテクチャがホストと一致している場合に、KVMなどのハイパーバイザーを使用することで高速化できるそう。 Dockerから利用されているのはユーザースペースの方です。ホストシステムのリソースを利用して異なるCPUアーキテクチャ用にビルドされたLinux実行ファイルを呼び出せます。
ユーザースペースエミュレーションの特徴としては下記です。
- System call translation
- POSIX signal handling
- ホストから来る全ての信号を動いているプログラムにリダイレクト
- Threading
cloneのシステムコールをエミュレートして、Hostのスレッドを作成し、エミュレートされた各スレッドに割り当てます
バイナリの名称は、 qemu-${taget-architecture} という形式になります。例えば、Intel64ビットCPUであれば、 qemu-x86_64 となります。
dockerからQEMUが呼ばれる仕組み
docker公式ブログを参考にしています。
QEMU統合は binfmt_misc handler に依存しています。Linuxが認識できない実行ファイル形式に遭遇したときに、その形式を処理するように構成されたユーザスペースアプリケーション(エミュレータ等)があるかをハンドラーで確認します。もし存在する場合には、その実行ファイルをハンドラーに渡します(参考)。
# 例えばJavaの場合… # 通常 $ java -jar /path/to/MyProgram.jar # binfmt_misc を利用する $ MyProgram.jar # 例えばQEMUの場合… # 通常 $ qemu-arm armProgram # binfmt_misc を利用する $ armProgram
関心のあるプラットフォームのをカーネルに登録しておく必要があります。
Docker Desktopを利用している場合には、既に主要なプラットフォームは登録済になっています。もしLinuxを利用する場合に、Docker Desktopと同じ方法で登録したい場合には、 linuxkit/binfmt イメージを動かせばよさそう(ドキュメントには docker/binfmt とあったけどGitHub行ったらArchiveされていたため)。
つまりマルチプラットフォームのビルドに必要になる要素は下記
ちなみに、binfmt_misc についてはこちらで詳細を確認しました。
/proc/sys/fs/binfmt_misc/register に対して、特定の形式で書き込むことによって対応づけが出来るようです。また、 grep binfmt /proc/mounts を実行して何も引っかからない場合には、まず、 mount binfmt_misc -t binfmt_misc /proc/sys/fs/binfmt_misc のようにマウントする必要性があるようです。
書き込む形式は下記のようになります。
# :<name>:<type>:<offset>:<magic>:<mask>:<interpreter>:<flags> :qemu-arm:M:0:\x7f\x45\x4c\x46\x01\x01\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x02\x00\x28\x00:\xff\xff\xff\xff\xff\xff\xff\x00\xff\xff\xff\xff\xff\xff\xff\xff\xfe\xff\xff\xff:/usr/bin/qemu-arm:CF :Java:M::\xca\xfe\xba\xbe::/usr/local/bin/javawrapper:
それぞれのフィールドについて軽くまとめてみました
- name
- 識別子
/proc/sys/fs/binfmt_miscの下に新しく追加されるときのファイル名。
- type
- MはmagicでEはextentionを意味する
- offset
- ファイル内のmagic/maskのオフセット
- byte単位でカウントされる
- 省略すると、デフォルトは0で入る
- magic
- binfmt_misc が見つけにいくバイト列
- mask
- 登録したmagicとファイルを照合する際に、無視したいビット列をマスクすることが出来ます
- interpreter
- どのプログラムを呼び出すか
# 登録内容を確認する例 $ cat /proc/sys/fs/binfmt_misc/jar enabled interpreter /usr/bin/jexec flags: offset 0 magic 504b0304
果たしてbitbucket pipelineでマルチプラットフォームビルドできる?
冒頭で書きましたとおり、モチベーションはここにあります。 bitbucket pipelineのノードのDockerのバージョンがv20.10になって、buildxがexperimentalから外れて実行できるようになったとしても下記のような課題があるため難しそうです。 冒頭で述べたとおり、特権コンテナが動かせないので…。
- ノードにQEMUがインストールされているか?
- もしされていない場合、ホスト側に実行ファイルを置かなくてはいけなさそうなのでキツい
- ここ見る限りdocker runの
--mountオプションが禁止されている
- binfmt_misc に登録されているか?
- もしされていなければ登録する必要があるが、ホスト側のファイルに書き込む必要があるので出来るかどうか?
逆にAMIの段階でこの辺が解消していれば、動かせそうな予感…! とりあえず、bitbucket pipelineのDockerバージョンが上がるのを一旦待とうと思います。
以上!