3ヶ月間の育休を振り返る
9月10日(水)から仕事に復帰します。3ヶ月間の育休が終わろうとしてます。
3日に2日は眠気と共にはありましたが、充実した日々を送ることができたように思います。
家事・育児にかなり集中できたおかげか、今のところは産後クライシスに陥ることなく3ヶ月間を過ごすことができました。我が子も健康です。
チームの方、上司、関係各所には感謝の気持ちでいっぱいです。復帰後に、しっかりとその旨をお伝えしていけたらと思います。
育休取得の目的は概ね達成
育休には以下のような3点の目的がありました。どれも概ね達成できたという認識でいます。
- 産後に体調が万全でないパートナーを支える
- 一通りの育児に関するタスクを習得する
- 赤ちゃんと触れ合う時間を長くする
それぞれ詳述します。
万全でないパートナーを支える
後陣痛や会陰切開に伴う痛みが産後発生すること、セロトニンの働きを助けるエストロゲンが急減してしまうことから、心身ともに万全な状態とは言い難い状態が続きます。
また、人によっては乳腺炎を発症して、もし悪化してしまった場合は40度の発熱を経験するケースもあるようです。
このような状態で、以前と同様に家事をしたり、慣れぬ育児にほぼ一人で取り組むのは困難であることは想像に難くありません。
そのため、家事と育児のタスクをバランスし、パートナーの負荷を下げることを育休の第一の目的としていました。
実際、新生児の育児は「何も分からない」の連続で、一人で取り組むのは厳しいように思いました。世のワンオペしているママさんとパパさん(赤ちゃんだけ先に退院する例もあるそう)はすごい。
泣いている原因が特定できず、ずっと赤ちゃんの泣き声を聞きつつ立ち尽くすような状況に陥ることがあります。2人いることで、気持ちを吐露して共有したり、一緒に解決に向かって議論したり、交代交代で一息つく時間を確保する等できたのが本当に助かりました。
悔やまれるのは、一番しんどい母子同室の1日目の夜にあまり助けになれなかったことです。
個室に入院していたので一緒に泊まることの出来るプランを選択できたようなのですが、聞き逃してしまったのか後から知りました。
細かいことを挙げれば、私の至らない点は多々あり、パートナーには脚を向けて寝られません。
養育者間で極度にピリついた状況になると、赤ちゃんにも影響するようです。
ケアとはなにか では「熟練した助産師さんが家庭訪問して赤ちゃんを抱き上げた時の強ばりで異常事態(後に養育者間の包丁沙汰があったと分かる)を察してヒアリングを行った」という話が紹介されていました。
エピソード記憶が未発達である赤ちゃんにこのようなことがあるのは非常に驚きです。
換言すると、赤ちゃんの成育そのものも重要ですが、養育者間の関係を良好に保つのも重要という示唆が得られそうです。
振り返ると、養育者間の関係を良好に保つために、この育休期間は必須であったと感じます。
一通りの育児に関するタスクを習得する
母親だけが育児に関するタスクが出来る状態はバス係数1です。バス係数は「チームのうち何人バスに轢かれたら破綻するか?」という数値で、チームの可用性や持続可能性について言及する時に用いられます。ユニークなのでつい使いたくなってしまいます。
バス係数1では様々な不便が生じるため、これを2以上に持っていきたい。それが育休を取得した2つ目の目的です。
要するに、パートナーが気晴らしに外出できるようにしたいし、パートナーの体調不良時にも対応できるようにしておく必要があります。パートナーが育児から開放される時間を作ることで、自分も罪悪感をあまり持たずに友人と遊ぶ時間を設けられるというちょっとした打算もあります。
一方が完全に上達しきってしまうと、「その人のやること」になってしまうことがあるように思います。
お互いが育児タスクに不慣れな中で一緒に模索していく作業のオーナーは1人よりも2人になりやすい、あるいは境界の緩いオーナーシップとなっていく感覚がありました。
一通りの育児タスクは出来るようになりました。ギャン泣きのときのおむつ替えと寝かしつけが比較的得意であるという自負があります。
とはいえ、爪削り(切り)はいつも緊張感があり慣れない…。顔への保湿も嫌がられてしまう傾向があります。まごついてしまうからでしょうか。
親に預けたり、保育所の一時預かりなども活用できるようにして、バス係数を更に上げていくこともやっていかないととも思っています。
振り返ると、以下の2つの記事が本当に有用だったと思います。
- 我が家のねんトレ - べんごちゃんのまとめノート
- 夜はだいたい9~11時間程度寝てくれるようになりました
- 寝ないときにすぐに抱っこするのではなく、レジ袋で音を鳴らしながら、お腹をトントンとして寝かしつけることをまず試してみています
- こたけ正義感絡みのコンテンツの中では「弁論」の次に好きです
- 赤ちゃんの泣きやみと寝かしつけの科学
- 腕の中で寝てから、7~8分くらいは抱いたままにしてからベッドに置くと、ほぼ1回でうまくいく
- 育児に関してはどうしても経験を基にした自論が多くある印象ですが、これは実験を通じて普遍性が確認された振る舞いなので、ある程度信頼性高め?と思いやってみたら上手くいきました
赤ちゃんと触れ合う時間を長くする
赤ちゃんと触れ合う時間を長くして得られるものとして、以下の2つを期待していました。どれも概ね達成できたという認識でいます。
- オキシトシンの産生を促し、自分の養育行動の積極性を強める
- 泣き声の特徴から原因を判別できるようにする
なぜ1つ目を期待していたかというと、そもそも子育てする前は、赤ちゃんと接することがあっても接し方がよく分からない状態で戸惑いが大きく、「かわいい」という感情を(我を忘れるほどには)持ったことがなくて不安だったというのがあります。
その不安はばっちり拭い去られました。めっっっっちゃかわいくて仕方がないです。
これまでの人生で口にした「かわいい」の回数は、この3ヶ月ですでに超えています。
なぜ写真ではこの実物の可愛さが伝わらないのか不思議です。写真の枚数も鰻登りになっています。
2つ目についてですが、正直そこまで細かい機微は感じ取れません。眠い / 空腹の2択だったら分かる気がします。
泣きと泣き止むために起こした行動の間にはっきりとした因果関係を見出すのが難しく、うまく経験を蓄積出来ていないからかもしれません。
眠いときの「うーうー」という泣き声がなんともかわいいです。
不確実性と共にあること
他者が自分の管理欲望を撹乱することに、むしろ人は安らぎを見出す。...すべてを管理しようとすればするほど、わずかな逸脱可能性が気になって不安に駆られるのです。むしろ秩序の撹乱を拒否しないことで不安は鎮まっていく。 -- 現代思想入門
と思ってポジティブに受け止めてみようとはするんですが、予期できないハプニングには思わずため息が漏れてしまうことも多いです。
動き回らないし、イヤイヤ言わないこの時期が一番楽なはずなんですが…。
とはいえ、事前に色んなメディアで確認していたよりも養育者の負荷は低い特徴を持った乳児だと感じています。ありがたいの一言です。
もしかしたら、辛い体験の方が記事や動画にしやすく、事前にそれらを目にする機会が多かったので、極端に大変な体験が多いと勘違いをしてしまったのかもしれません。利用可能性ヒューリスティックというやつでしょうか。
「吐き戻し(多めの溢乳含む)」と「うんち漏れ」、「ド早朝に起きる」の3つが今よくあるハプニングです。
吐き戻しは服にかかってしまうと当然お着替えが必要になるのですが、多いときは1日に4回ほどお着替えをします。ガス衣類乾燥機を導入しておいて良かったと心から思います。
満腹中枢が存在する視床下部は生後3ヶ月ごろから働き始めるようなのですが、まだ発達途中で飲みすぎちゃうことがあるんでしょうか。ベビースケールがあれば、よりもっともらしい分析ができるのかもしれません。
抱っこ紐でお出かけする時にお腹が圧迫されてしまうのか、よくお口からミルクがたらり。使い始めてから、ずっと紐の長さを調整をし続けています。難しい。
moonyのテープおむつを使っていますが、ゆるうんちポケットが機能する背中側ではなく太ももから漏れてしまうことが多いです。やたらと動いた後や、寝ている姿勢以外のときにうんちをすることが多いので、太もも側に隙間が開いてしまうのかもしれません。
うんちが手に付いてしまうのはもう慣れっこなのですが、服についてしまった染みを落とすのがやや大変です。服だけならまだ良いのですが、スワドルやシーツにまで被害が及ぶことがあり、急に時間を要することがあります。
上述のものよりやや頻度は落ちますが、ド早朝に起きるというのがあります。
1日のリズムが整ってきて、非常にありがたいことに、基本的には夜20時30分から朝7時30分くらいまで寝てくれます。ただし偶に4時台に起きてしまうことがあります。
寝返りはまだうてないのですが、寝てる間の脚の動きが激しくて、体全体が回り頭がベビーベッドの壁にめり込んでしまうのが原因と推測しています。
一応、ドアを2枚挟んでいるのですが、体が大きくなるにつれて声が大きくなったのもあって、夜中に泣くと起きてしまいます。
お出かけはまだ回数は少ないのですが、事前の情報収集の重要さが身に沁みました。
赤ちゃんの(特にお腹へっているときの)泣き声は、大人にとって不快なので(生存上そうであるべき)、泣いているときは周囲の人の注目を浴びると分かっていたつもりですが、思っていたより色んな人と目が合います。なんだか焦ります。
授乳室の位置は一番近いところだけでなく、複数確認しておいたほうが良さそうですね。
ベビーカーでの移動になったときにも色々考慮が必要そう。とりあえずは、最近リリースされた NAVITIME for Baby を試してみようかなと思います。
育児以外の過ごし方
2ヶ月目はまとまった時間の余裕があったので、別のことに時間を割きやすかったです。
最初の1ヶ月はドタバタしていて、3ヶ月目は我が子の起きる時間が長くなったため、あまりまとまった時間は取れなくなりました。
最近、日中に関しては、「2時間起きる → 30分~1時間寝る」を繰り返しています。昼寝の時間がなかなか伸びず、眠くてグズっている時間がやや長いかなという気がしなくもないです。
料理
この3ヶ月間のご飯の99.5%は私が作っていました。完ミであれば、育児/家事のタスクを全部均等に割ることもできると思うのですが、うちは完母寄りの混合だったので、家事のタスクを多めに引き受けることにしていました。
正直こんなに毎度ちゃんと作ったのは初めてでした。ちょっとだけ専業主夫の方の気持ちが分かったかもしれません。
「美味しく作りたい」「自炊のクオリティを上げたい」という気持ちは以前よりもかなり強くなりました。
というのも、赤ちゃんがいることでパートナーと外食できるお店の選択肢がぐっと減るためです。お酒が出るお店やラーメン店、いい感じのイタリアンetc には連れていけません。一時預かりは制限があるし、両親に預けるにしてもまだ早いように感じられました。
短期間に頻度高くやるとフィードバックのサイクルが回りやすいのか(?)、学びを得やすく、上達も実感しやすかったです。
読書
仕事をしていると、仕事に関連する本ばかりを手に取ってしまうので、敢えてそれらを避けました。
換言すると、エンジニアリングマネージャやソフトウェアエンジニアリングに関するもの 以外 を読んで、この3ヶ月間を過ごしました。
一番多く手に取ったのは、教育社会学に関する書籍かもしれません。新書・文庫で入門する教育社会学ブックリスト を参考にして幾つか読みました。統計データや歴史的経緯、エスノグラフィを通した考察を読んでみて、教育というのは経験から自説を持ちやすい分野だと痛感しました。
ミステリーや哲学、様々な分野を横断して俯瞰しつつ世界を書き下ろす系の本についても手に取ってみました。ミステリーを読むのはかなり久しぶりでしたし、哲学に類する本(入門 of 入門書ではありますが)を読むのは初めてだったのではないかと思います。
この期間で読んで、一番記憶に残っているのは ヒルビリー・エレジー だと思います。マイケル・サンデルの 実力も運のうち 能力主義は正義か? につながる部分がありつつも、実話とは思えないほど手に汗握る描写に目が離せなくなりました。
家事のお供になったのは、 audiobook.jp でした。
バッタを倒すぜアフリカで はめちゃくちゃ面白かった。大学生のときに聞いてたら、院進するために頑張っていたかもと思わされました。書籍も思わず買いました。
内容はもちろんのこと、ナレーターさんも素敵でした。ティジャニのときの喋り方が最高に愛らしくて…。
Audibleのときにデジタルボイスのオーディオブックを聴いてみたりしましたが、人には遠く及ばない点があると感じました。
人の朗読の方を良く感じる理由についてすべてを言語化することは出来ないのですが、この上手く言語化出来ない部分にこそプロの技がありそうです。
仕事に復帰した後に、「なぜ働いていると本が読めなくなるのか」という状態になりそうですが、比較的負荷なく読めそうな再読で馴らしつつ、読書を継続したいところです。
日記
ネガティブな記憶は想起されやすいが故に記憶に残りやすいですが、ポジティブな記憶はあまり記憶に残っていません。
DMN(Default Mode Network)は安静時や何もしていない時に作動する脳の部位だそうです。自分に関する情報を処理するため、過去の記憶の傷跡にアクセスし、自分に関する愚痴あるいはネガティブな物語(予測)を作り出す機能があると考えられています。そのため、ネガティブな記憶の方がアクセスされやすく記憶に残りやすいのかなと私は思っています。
ちなみに、このDMNはアルツハイマー型認知症では活動が弱くなり、それが見当識障害として表出し、例えば「健康であるように取り繕う」という態度を取ったりするようです。
ポジティブな記憶をできるだけ残しておきたいと思って、日記を書き始めました。
仕事をしているとなかなか続かないし、育児に関しては描くことが色々あるのでよい機会であったかなと思います。
松村北斗、内山昂輝、トンツカタン森本
なんの気力も湧かないときはこの3人が出ているコンテンツを観ます。
日曜夜の GOスト で曜日感覚を取り戻して、ゴミ出しをこなせていたと言っても過言ではありません。
曜日感覚といえば、毎週木曜に配信される 銀河鉄道ミルキーサブウェイ も助けになりました。カートというキャラクターが結構刺さってます。
まとめ
職場からサポートいただき、3ヶ月間の育休を取得することが出来たのは、本当にありがたいという気持ちです。
ちょっと埃を被った仕事の知識やスキルで3ヶ月ぶりの仕事はちゃんと出来るだろうか(寝かしつけの縦揺れで、唯一足腰は鍛えられているが活かす場はない)。休み前の自分のミスが、自分のいぬ間にチームに負荷としてかかっていないだろうか…。
などと、思いを巡らせています。
我が子がド早朝に起きないように祈りつつ、明日に向けてゆっくり寝ます。
新生児の子育て奮闘記
我が家に新生児を迎えてから丁度2週間が経過したので、日々の様子を雑多にまとめてみます。
育児のタスク
寝かしつけを除けば、 想像していたよりも早く慣れることができました。寝かしつけについては後述します。
産院での面会中に、おむつ替え・ミルク・げっぷ・沐浴といった基本的なケアを(助産師さんの指導のもと)実際に体験できたことが、非常に役立っています。
面会前にYouTubeなどで予習するきっかけになりましたし、赤ちゃんを家に迎えるまでの間に復習する時間も確保できました。
女性は出産時に(愛情ホルモンと呼ばれる)オキシトシンのシャワーを浴びる一方で、男性は子育てに積極的に参加することで徐々にオキシトシンが分泌されるようです 1 。
子育てを楽しく感じ、愛情を持って接することができるようになるためにも、赤ちゃんとの触れ合いの機会を確保することを心がけています。
ちなみに、赤ちゃんの泣き声からニーズを聞き分ける能力には男女差がないという研究結果もあるそうです。ただし「子どもと接触する時間が長い父親であれば」という条件付きですので、そういった意味でも接触時間を意識的に増やすようにしています。
おむつ替え
産後2,3日しか見られない胎便と対面できたのは、貴重な経験でした。皮膚にこびりついて全然取れなかったので、力強くごしごしと拭き取りました。
おむつ替えの頻度は当初想定していたよりもずっと多いことに気づきました。
膀胱内に尿がたまり、膀胱内圧が高まると伸展受容器が刺激を受けます。大人の場合はその刺激を大脳が処理し尿道括約筋を弛緩させますが、赤ちゃんの場合は大脳を介さず脊髄で直接刺激を処理するため排尿の頻度が高くなるそうです。
赤ちゃんが不快に感じるのは、排尿後の不衛生さではなく、排尿自体や濡れたことによる皮膚の体感温度の変化のようです。
尿意(や睡魔)は赤ちゃんにとってはまだ不快な感覚のようです。大人はその後にスッキリした気持ちが待っていることを知っていますが、生後6ヶ月頃までは「時間」という概念がなかったり、生後3ヶ月頃から形成され始める手続き記憶がまだ備わっていないためか、単純に不快として感じてしまうようです。
ちなみに、家に来て最初におむつ替えてる最中にうんちを噴射されてめちゃくちゃ笑いました。
GUのセール品のトップスを何枚か買い込んでおいて本当に良かったです。ガード下げてるときに攻撃するのは反則でしょう。
ミルクとゲップ
哺乳瓶を嫌う赤ちゃんもごく少数ながら存在すると聞いていたので、スムーズに飲んでくれて安心しました。ただ、生後3ヶ月頃から突然哺乳瓶を拒否するケースもあると聞いているので、まだ油断はできないと考えています。
赤ちゃんはコイやナマズと同様に唇の周辺でも味を感じるようです。吸啜反射を促すために哺乳瓶の乳首を口に入れる必要がありますが、まず唇の周りを優しくちょんちょんと触れることで口を開けてもらうよう工夫しています。
飲むのが止まったときには、少し揺らすとまた吸い始めてくれます。
当初は哺乳瓶を煮沸消毒していましたが、大きな鍋を常に確保しておくのが不便だったため、最終的にはピジョンのミルクポンを使用することにしました。
産院からもらったビタミンK2シロップを与えていますが、母乳で不足しがちなビタミンK2を粉ミルクで補うこともでき、より安心感があります。 ビタミンK2は血液凝固に重要な役割を果たすため、不足すると止血機能が弱まってしまうそうです。
哺乳瓶で授乳すると空気も一緒に飲み込む可能性が高くなるため、必ずゲップをさせるようにしています。 最初は縦抱きでゲップをさせようとしましたが、どうしても赤ちゃんの口と鼻を塞いでしまいがちだったため、助産師さんに教えていただいた膝を使う方法に変更しました。 体内に空気が溜まると不快感から寝付けないことが多いように感じるので、5〜10分程度かけてじっくりとゲップを促すようにしています。
沐浴
リッチェルのベビーバスを浴室で使用しています。 YouTubeの沐浴動画ではシャワーを使っている例が少ないようですが、産院での沐浴講習でシャワーを使う方法を教わったため、泡を流すときはシャワーを活用しています。
お湯に入れたりシャワーで流したりすると、モロー反射が起きて体勢が不安定になるため、(背中を洗う時以外は)常に左肘ごとベビーバスに入れた状態で首と背中をしっかり支えています。 下半身がお湯に浸かったままだとボディソープでうまく洗えないため、下半身を洗う際にはベビーバスに対して赤ちゃんを斜めにし、一時的に下半身を水面から出して洗うようにしています。 背中を洗う時は、右腕に赤ちゃんの両手と顎を乗せ、左手で背中とお尻を優しく洗います。
タオルで拭いて保湿している間は、体の水分が蒸発する際に体温も奪われるためか、泣き出してしまうことが多いです。バスタオルで体の隅々や髪の毛まで丁寧に拭き取ります。
あまりにも激しく体を動かしている場合は、顔の保湿やへその消毒は服を着せてから行うとスムーズです。
不思議なことに、コンビ肌着の股下のスナップを留めた瞬間に落ち着くことがあります。そんなに変わるかなあ(?)
触れ合い
寝かしつけのついでに触れ合っているイメージです。
今後は、定期的にくすぐって赤ちゃんが「身体の輪郭」をどういうペースで認識しているかも確認してみたいと思っています。
新生児の視力は0.01程度で、視界はモノクロに近く、さらに2次元に見えていると言われています。父親と母親が別の人物であることや、「母親」は「母親」であるという同一性にもまだ気づいていない段階です。
赤ちゃんは生まれた時から人間の顔の形状を好む傾向があるようです2。そのため、約30cmの距離に自分の顔が来るように抱っこする機会を多く設けるようにしています。 また、母国語のリズムは胎内にいる時から認識し好む傾向があるとも言われているので、まだ言葉の意味は理解できないでしょうが、積極的に話しかけてみるようにしています。13世紀のフリードリッヒ2世の実験やルネ・スピッツによる第二次世界大戦時の孤児院の調査から、コミュニケーションやスキンシップがないと人は育たないことが示唆されており、話しかけることにはなんらか意味を持つのかもしれません。
我が家の寝かしつけルーティン
1. 温度のチェック
- 摂氏23〜25度だったらOK
- コンビ肌着1枚(+ おくるみ)の場合
- CuboAiというベビーモニターで温度を計測しています
- 2方向に窓がある部屋にベビーベッドを置いていましたが、日中の室温が高くなりすぎたため部屋を移動しました
- アルゴンガス入りLow-E複層ガラスの断熱性の限界を実感しました
- 裏を返せば冬は暖かく過ごせそうです
- 汗をかいていないか、手足だけでなく胴体も冷えていないかなども重要なシグナルとして確認しています
2. 授乳間隔/ミルク間隔のチェック
- 母乳の場合は1.5時間以上、ミルクの場合は3時間以上が前回から経過しているか確認します
- ぴよログを使って授乳とミルクの記録をつけており、夫婦で情報を共有しています
- 睡眠時間や排泄についても同様に記録しています
3. おむつのチェック
- おしっこをするとおむつの色が青く変わるタイプを使用しているので、すぐに確認できます
- うんちの場合は基本的に匂いで判断できます
- ただし胎便は匂いがほとんどしないため、おむつの中を定期的に確認する必要があります
4. おくるみでくるむ
4以降は、The Science of the 5 S's を参考にしています。 これは5Sのうちの一つ、Swaddling(おくるみ)にあたります。
- おくるみで包むことでノンレム睡眠時間が延び、覚醒が減少するとされています 6
- 「おにぎり巻き」と呼ばれる包み方を実践しています 7
- ただし、寝返りができるようになった後はSIDS(乳幼児突然死症候群)のリスクが高まるため、おくるみの使用を中止する必要があります 8
5. ビニール袋をすり合わせる音を聞かせる
CuboAiの機能で流すホワイトノイズや扇風機の音では何故か効かない。
おむつを捨てる匂いを抑える袋を利用して、カサカサした音を出すと泣き止んで入眠してくれるケースがある。
6. 縦揺れする
5Sのうちの一つである、Swing(揺らす)を実践しています。 赤ちゃんの泣きやみと寝かしつけの科学 - 東京科学大学 黒田研究室 で説明されている「輸送反応」を誘導する目的もあります。
- 左上腕に赤ちゃんの頭を乗せ、新生児の視力(約0.01)でもうっすら見えそうな30cm以内に自分の顔が来るようにします
- 子宮にいる胎児の段階から、顔に似た形状を好むことが研究で示されています
- 上半身はしっかりとホールドして動かさないようにしながら、スクワットをして縦方向に揺らします
7. 保持したまま見守る
赤ちゃんの泣きやみと寝かしつけの科学 - 東京科学大学 黒田研究室 で言及されているように、抱っこしている状態で移行する「ステージ1睡眠」では、ちょっとした刺激(親との体の分離など)で目が覚めてしまうため、5〜8分程度はそのまま抱き続けるのが良いとされています。
ただ、私自身の経験では、長く抱き続けている間に逆に起きてしまうこともあり、眠りについたら約1分程度で静かに置いた方が入眠を促しやすいように感じています。 研究では主に生後2ヶ月以降の乳児を対象にしていることや、個人差があることも考慮する必要があるかもしれません。
8. ちょっと泣いても一旦見守る
赤ちゃんは30〜60秒程度で自己なだめ(self-soothing)によって再入眠することがあります。
米国小児科学会(AAP)による Self-Soothing: Help Your Baby Learn This Life Skill でも、短時間泣いている赤ちゃんをそっと見守るのは「泣かせっぱなし」ではなく、self-soothingを身に付けるための大切なプロセスであると説明されています。
9.「やったか!?」
「ようやく寝てくれた…」と夫婦でホッとしてハイタッチした瞬間に、再びギャン泣きが聞こえてくることもあります。
改めて1のステップに戻って確認です。10分前におむつを替えたばかりでも、再度おしっこしていることも珍しくありません。
医療機関への連絡をするか判断する危険サインが見当たらないかを念のために確認します。
精神的に消耗しそうなときは、ワイヤレスイヤホンでオーディオブックを聴きながら赤ちゃんの様子を見守るようにしています。
最近は、audiobook.jp で バッタを倒すぜアフリカで を聴いています。めちゃくちゃ面白いです。書籍も購入してティジャニを応援しようと思います (?)
現時点での情報収集
- ベビまよ (Podcast)
- 書籍
- 初めての育児新百科
- 基本的な情報はこれでほぼカバーできると感じています
- 脳研究者 育つ娘の脳に驚く
- 芸人のこたけ正義感さんの奥様が書かれていた我が家のねんトレ - note.comで知りました
- 赤ちゃんの行動の背景にある脳の発達段階を知ることができます
- 今回の記事で言及している事柄の一部はこの書籍から引用しています
- 赤ちゃんはことばをどう学ぶのか
- ゆる言語学ラジオで水野さんが言及されていた通り、実験デザインが興味深いです
- 初めての育児新百科
- 自治体での両親学級や助産師訪問
- YouTube
- 生成AI
- AAPや日本小児科学会など信頼できる情報源に限定するプロンプトを使い、reasoningモデルで信頼性の高い情報を得るよう工夫してみています
- テレビ番組「夫が寝たあとに」(テレビ朝日)
- 友人
- 偉大な先輩方がたくさんいるのだ
使っているツール
- CuboAI
- 泣き声の通知や顔覆いの検知機能を活用しています
- ダイニングにタブレットを設置して常に赤ちゃんの様子を確認できるようにしています
- おむつ替え時のナイトライト機能が思いのほか便利です
- ホワイトノイズを流す機能も利用しています
- ぴよログ
- 授乳やミルクのタイミングを夫婦で共有するのに非常に役立っています
- 日々の睡眠時間のパターンも確認できます
- 排泄記録もとることで、便秘傾向なども把握できます
- Siriと連携することができるため、おむつを替えながら音声で入力することができます
- 母子手帳アプリ 母子モ
- 予防接種のスケジュール管理に使用しています
- 家族アルバムみてね
- 親族に子どもの写真や動画を共有するために活用しています
これから
何よりも健康にすくすくと成長していってほしいと願っています。 まずは目の前の1ヶ月検診でしっかりと体重が増えていることを確認したいです。
育休明けにどのように仕事と育児を両立するかは、正直なところ不安に感じています。
現在は料理と買い物を全て担当し、その他の家事も6〜7割ほど引き受けています。育児に関しても寝かしつけ、沐浴、おむつ替え(頻度は少なめ)、時折のミルクを担当しています。深夜の授乳とそれに付随する作業はパートナーに担ってもらっているため、もっと積極的に家事を負担するべきと感じています。
育休が明ける9月上旬までに赤ちゃんのサーカディアンリズムをある程度確立し、self-soothingの能力を育むことができれば、夜間の負担を軽減し、夫婦ともに消耗の少ない状態を作れるのではないかと期待しています。
朝7時頃にカーテンを開けて日光を取り込み、夕方18時ごろに沐浴を行い、その後は部屋を暗くすることでサーカディアンリズムの確立に努めてみています。
最近、中公新書の ケアとは何か という本を読みました。 イギリスの小児科医ウィニコットは次のように論じています。
育児のおけるケアの働きかけが、子どもに「自分というものが存在している」という実感を生む。 <私> が初めからあるわけではなく、ケアこそがあかちゃんを生み出す。
育児は「存在を支えるためのケア」でもあることを頭の片隅に置きつつ、引き続き育児に取り組んでいきたいと思います。
夕方の時間は寝てもすぐに起きてしまうのよね…どうしたらいいんだろうか… (?)
縦揺れでスクワットの回数が増えてきており、家から出る機会は減ったのに脚力は鍛えられていそうである。
- Father's brain is sensitive to childcare experiences↩
- Eye contact detection in humans from birth↩
- Systematic review of the impact of feed protein type and degree of hydrolysis on gastric emptying in children | BMC Gastroenterology | Full Text↩
- Lactation in the human - PMC↩
- Urination during the first three years of life↩
- The effect of swaddling on infant sleep and arousal: A systematic review and narrative synthesis - PMC↩
- よっぴ👶タレ眉毛0歳ベビー | #おくるみ #おくるみの巻き方 助産師さんが教えてくれた バスタオル1枚で安心してくれる おにぎり巻き #baby #👶 #新生児 #新生児育児 #育児絵日記 #justborn #赤ちゃん #ベビー #あかちゃんのいる暮らし #0歳 #0歳児ママ... | Instagram↩
- Sleep-Related Infant Deaths: Updated 2022 Recommendations for Reducing Infant Deaths in the Sleep Environment↩
2024年に読んだ書籍を振り返る
2024年が終わりましたので、昨年読んだ本をざっくりと振り返ろうと思います。
去年はちゃんと年末にpublish出来ているらしい。
振り返って気づいたこととして、今年は大乗仏教に関する本を一冊も読んでいないことが挙げられます。昨年は『100分de名著 維摩経』を読み、大乗仏教に対する興味の幅が広がったように感じましたが、なかなか丁度良い本を見つけることができず、そのまま止まってしまっています。自分の菩提寺の宗派を考慮すると、禅宗についてさらに深掘りしてみるのも良いかもしれません。ZORNみたいなこと言ってますし(?)。洗濯物干すのも修行。
また、再読をもっと積極的に行っても良いのではないかと感じています。本当にすぐに内容を忘れてしまうためです。あまりにも忘れてしまうことが多いため、最近では印象に残った本についてブログに読書記録をつける試みを始めました。
余談ですが、本の内容を思い出そうとすると、なぜか本を読んでいた際の自分の状況を一緒に思い出してしまうことが多いです。
たとえば、「これはクラフトビールを飲みながら読んだ本だ」とか、「LUMINEのエスカレーターで読んだ本だ」などです。本の内容をしっかり覚えていたいのに、どうしてこのように状況ばかりが浮かぶのか、不思議に思っています。
2024年に読んだ本は19冊でした。
- チームを動かすIT英語実践マニュアル
- 統計学が見つけた野球の真理
- スタッフエンジニア マネジメントを超えるリーダーシップ
- 100分de名著 渋沢栄一『論語と算盤』
- なぜあの人の解決策はいつもうまくいくのか?
- 認知バイアス
- 物語 イギリスの歴史(上)(下)
- 麻雀1年目の教科書
- 地面師 他人の土地を売り飛ばす闇の詐欺集団
- お金のむこうに人がいる
- 無(最高の状態)
- 他者と働く
- 漫才過剰考察
- 最高の老後
- 年金不安の正体
- ホワイトカラー消滅
- エレガントパズル
- プロダクトマネージャーのしごと 第2版
チームを動かすIT英語実践マニュアル
こちらは、チームのメンバーが紹介してくださった本です。私は日本と海外のSREチームを兼務しており、東南アジアのメンバーとの英語でのコミュニケーションが発生するため、英語力、特にリスニングとスピーキングのスキル不足に悩んでいます。雑談を円滑に行うことももちろん重要ですが、仕事上で必要となるコミュニケーションの表現をしっかりと押さえることが大切だと考え、本書を手に取りました。
シチュエーションが実際の業務に近い内容で、そのまま利用できる表現も多く、大いに活用できたと感じています。
特に、Unit 5 の 1on1 に関する内容が個人的には非常に気に入りました。
リスニングやリーディングは少しずつ上達しており、直近のTOEICでは820点を取得しました。大学時代に受験した際のTOEICは500点台だったと記憶していますので、この10年間でのTOEIC難化も踏まえると、確実に成長していると実感しています。しかしながら、英語でのコミュニケーションがまだ十分に円滑とは言えず、更なる向上が必要だと強く感じています。
統計学が見つけた野球の真理
BLUE BACKSのセールがあった際に、つい購入してしまった一冊です。野球はほとんど観なくなって久しいのですが、高校野球をたまに観ることがあり、社会人になってからは西武ドームや神宮球場に野球観戦に行ったこともあります。最近は、帰省するたびに嘆いている西武ファンの親の姿を見て、パ・リーグのペナントレース状況を知る程度です。西武鉄道という会社自体は、2004年の上場廃止時と比較してかなり回復している印象を受けますが、球団の成績はそれとは逆の状況にあるようです。今年は紀尾井町ガーデンテラスの売却益があるものの、その資金はおそらく球団ではなく不動産事業に回りそうで、来年も親の嘆きが聞こえてきそうです。
本書は冒頭から非常に魅力的でした。「そのプレーにどのくらい価値があるのか測るには、得点期待値と得点確率という物差しを使う」「無死一塁のランナーをバントで送って一死二塁にする戦術に、得点期待値を上げる効果はない」といった記述があり、これに心を掴まれました。
やはり「掴み」の重要性を改めて感じました(無理やり?)。令和ロマンがM-1決勝で「終わらせましょう」と言ったときのワクワク感を思い出します。ちなみに真空ジェシカの1本目が一番好きでした。
「無死一塁で送りバント」なんて、非常によくあるパターンです。少年野球や高校野球では定石中の定石ですし、プロ野球でもよく見られる戦術です。それが統計的に覆されているのは、とても興味深いと感じました。この問題は「犠牲バントの損益分岐点」と呼ばれているそうで、NPB2021年シーズンの統計によると、出塁率が .127 以上であればヒッティングの方が得点期待値が高いとのことです。
その後の章では、「投手として」「野手として」「バッターとして」、純粋な能力をどのように測るかにフォーカスしています。具体的には、球場の特性やピッチャーの場合の自陣守備の巧拙といった、純粋な能力評価のノイズになる要素を取り除く必要性について論じられています。また、守備におけるUZR(Ultimate Zone Rating)に代表されるように、どのデータを採用するかで結果が異なったり、グラウンドの形状や選手のポジショニングといった、まだ考慮されていない要素があることも触れられています。
これらは、私が所属するチームで提供しているプラットフォーム(例えばCI/CD基盤やEKSクラスタ)のSLO計測にも通じる部分があるように感じました。どのようにすればプラットフォームとしての品質を純粋に測ることができるのか、という課題に似ていると感じたため、より興味深く読むことができたのかもしれません。
スタッフエンジニア マネジメントを超えるリーダーシップ
以前配信されていたポッドキャスト「e34.fm」で言及されていた本だったように記憶しており、そこから興味を持って読み始めました。また、https://staffeng.com/ については以前から知っており、本書の冒頭で説明されている一般的な4つのアーキタイプに関する内容までは読んでいました。しかし、それ以降は特に読んでおらず、この書籍を改めて手に取りました。
「スタッフエンジニアとは何をする人なのか?」という疑問を強く持っていました。シニアエンジニアよりも影響範囲が広く、組織に大きく貢献できる存在であると考えていましたが、それをどのような行動で実現するのか、本書を読むまでは自分の中で明確ではありませんでした。
技術的な方向性を設定および修正し、スポンサー(支援者)あるいはメンター(助言者)として行動し、組織の意思決定をサポートするためにエンジニアリングの状況を伝え、探求し、そしてターニャ・ライリーが「接着剤」と呼ぶ役目をこなすのである。
「接着剤」については、https://www.noidea.dog/glue/ で "glue work" として紹介されており、ソフトウェアエンジニアとしては評価されにくいものの、プロジェクトやチームの成功に不可欠なタスク(チーム運営やサポート、プロセス改善、メンバー支援、技術以外の雑務、コミュニケーション促進)を指すとされています。
エンジニアリングマネージャになってから感じたことは、自分が glue work に手を付けやすいという点です。チーム全体のアウトプットが評価の対象となるため、自分個人の成果物が求められるわけではなく、逆にメンバーにはわかりやすい成果物がある方が評価しやすい(上位のマネジメント層にアピールしやすい)ためです。その結果、メンバーの glue work を積極的に引き受けてしまう動機が生まれやすいと感じます。
ただし、これは行き過ぎると悪影響を及ぼす可能性があります。マネージャはよりレバレッジの高いタスクに注力すべきですが、それに集中できなくなるリスクがあります。また、glue work の中にはメンバーが学ぶべきスキルや責任感を養える要素が含まれており、その機会を奪ってしまう可能性があります。さらに、組織全体で glue work が「重要な仕事」として認識されないことも懸念されます。
話がそれてしまいましたが、スタッフエンジニアもマネージャと同様に、組織全体のアウトプットにフォーカスした立場にあるようです。
本書には、スタッフエンジニアが発展し続けるために大事なこととして、以下の点が挙げられていました。これは新任スタッフエンジニアから信頼されるリーダーに求められる要素でもあり、スタッフエンジニアに期待される行動とも言えそうです。
- 重要なことに力を注ぐ
- エンジニアリング戦略を立てる
- 技術品質を管理する
- 権威と歩調を合わせる
- リードするには従うことも必要
- 絶対に間違えない方法を学ぶ
- 他人のスペース(余地)を設ける
- ネットワークを築く
これらについて詳細な説明がなされており、そのどれもが非常に興味深い内容でした。「重要なことに力を注ぐ」や「技術品質の管理」、「権威と歩調を合わせる」、「リードするには従うことも必要」などは、シニアエンジニアとして重要な事項である印象を受けました。また、「他人のスペース(余地)を設ける」や「ネットワークを築く」はマネージャとしても欠かせない要素だと思います。
本書の後半を占める第5章では、スタッフエンジニアの実際のストーリーが紹介されており、ラスさん、バートさん、ケイティさんのエピソードが特に印象に残りました。ただ、今読んだらまた別の人のエピソードが気になるかもしれません。この本は近いうちに再読したい一冊です。
100分de名著 渋沢栄一『論語と算盤』
以前、NHKオンデマンドで『100分de名著』を流し観していた時期がありました。ちなみに、『維摩経』を知ったのもそのきっかけです。
ドラマ『青天を衝け』は観ていないのですが、新一万円札の肖像画が渋沢栄一に変わるということで、少しミーハーな気持ちで動画を観てみました。すると内容が非常に面白く感じられ、書籍も購入しました。
子曰く、吾十有五にして学に志す。三十にして立つ。四十にして惑はず。五十にして天命を知る。六十にして耳順ふ。七十にして心の欲する所に従ひて矩(のり)を踰えず(こえず)
この言葉は、「論語」に登場する孔子の有名な一節で、志について触れています。本書の著者は、渋沢栄一が実業界に飛び込んだことを立志と語っていますが、それは天命に当たるものではないかとも言及しています。志と天命の違いは、「自分の可能性に目を向けるか」「自分の限界に目を向けるか」という視点の違いに由来するのだそうです。この部分を読んでから、自分にとっての「立志」や「天命」とは何だろう、と考えるようになりました。
また、孔子でも60歳になるまでは人の意見を素直に聞けなかった、というのは少し救いにも感じられました。
本書では、「信頼」や「信用」が『論語』と『算盤』の中核にあると述べられています。明治時代、商業道徳が劣化し、イギリスで渋沢栄一が直接苦情を受けた経験があったそうです。そのため渋沢は、『論語』を使って商業道徳の重要性を訴えました。道徳の獲得には、「常識を作り、それに基づいた良き行動のルールを見つけ、それを習慣化すること」が必要です。渋沢は、常識を形成する上で「智(知恵)、情(情愛)、意(意思)」のバランスの重要性を指摘しており、このバランスがなければ、ロジックや感情的な納得、目標の一致が取れず、相手と妥当な合意を作ることは難しいと述べています。この部分を読んで、自分にはこの3つのバランスが欠けていることがあると感じ、考えさせられました。
さらに、渋沢が掲げた「合本主義」と資本主義の大きな違いは「公益を追求する」ことだそうです。自己の利益だけを求めても、最終的には社会全体や自分自身の利益にならない、という考え方を改札に例えています。「合本主義」で動くことがモチベーションとなる世の中が実現すれば良いと感じましたし、大いに共感できる考え方でした。
なぜあの人の解決策はいつもうまくいくのか?
本書は、主にミドルマネージャーを対象とし、レバレッジを活用することの重要性が語られています。『HIGH OUTPUT MANAGEMENT』で触れられるように、マネジメント活動における意思決定やナッジングにおいて「ストックとフロー」の視点で課題の構造を明らかにするシステム思考は、私にとって非常に魅力的なツールに感じられました。
書き方は頭に入ったものの、実務への活用がまだ不十分です。そのため、中盤にある「システムの原型」についても目を向けづらいという悪循環が生まれてしまっています。年始の業務においては、意識的にシステム思考を活用してみようとしています。
認知バイアス
「根本的な帰属の誤り」などの認知バイアスについて考慮したGitLabのValuesを読んでいて、認知バイアスについてもっと深く理解する必要があると感じ、手に取った一冊です。こちらもBLUE BACKSのセールで購入しました。
特に印象に残ったバイアスについていくつかご紹介いたします。
1つ目は「利用可能性ヒューリスティック」です。リハーサル効果との組み合わせにより、「頻繁に出会うもの=思い出しやすい=その出来事は頻繁に起こっている」という方程式が成立するという点が興味深かったです。メディアは珍しい出来事ほど頻繁に報道するため、現実とは異なる印象を抱いてしまうことになります。この錯覚は『ファクトフルネス』でも言及されていました。
2つ目は「代表性ヒューリスティック」です。現在有力とされるカテゴリ化の方法は、プロトタイプとの比較照合によるものです。プロトタイプは帰納的推論によって形成されますが、その形成には事例との遭遇が必要です。ただし、少数のサンプルから誤ってプロトタイプ「のようなもの」を作ってしまうことが多いのです。このプロトタイプは、目立つサンプルに基づくため、カテゴリの代表例としては不適切であることが多いのです。このバイアスは国籍や人種に適用され、社会的ステレオタイプを形成します。「世界一周で価値観が変わる」という話にやや懐疑的な思いがありましたが、数多くのサンプルを得て社会的ステレオタイプから解放されるという観点からすれば、確かに価値観が変わる可能性があると感じました。
3つ目は「確証バイアス」です。これは原因を一つに絞り込み、そこだけに集中してデータを集める傾向を指します。たとえば、第一印象が重要であることもこのバイアスに関連しています。「この人は爽やかで優しそうな良い人だ」と感じると、その証拠ばかりを集め、仮説を覆すことが難しくなります。
4つ目は「ひらめきは無意識的な学習の成果である」という点です。創造が突然のひらめきによるものという通説とは異なり、常識的な捉え方に対応する制約を緩和し、試行錯誤を重ねることで創造的な成果が得られるという主張です。試行を重ねる中で無意識的システムが洗練された試行を行い、その結果として「できた!」と気づくのだそうです。失敗を重ねることで制約を緩和し、創造の芽を育てることができるという点に感銘を受けました。
本書の最終章では、「認知バイアスというバイアス」というテーマが取り上げられています。このテーマには少々驚かされましたが、文中でも「ちゃぶ台返し」という表現が使われており、本書全体を振り返る上で非常に印象的でした。
物語 イギリスの歴史(上)(下)
6月のイギリス旅行を楽しむために読んだ2冊です。
本書はイギリスの歴史すべてを網羅するものではなく(膨大すぎるため)、主に「王権と議会」を中心に展開されています。そのため、ノルマン征服まではやや駆け足で進みますが、それでも興味深い内容であり、別の書籍でさらに詳しく追ってみたいと感じました。
面白いなと思った部分を以下に簡単にまとめてみます。
イングランド(「アングル人の土地」という意味)と呼ばれるブリタニア中央部と南部には、アングロサクソン人が5世紀前半から150年にわたり渡来しました。この際、原住民を殺戮し、西端に追いやられた人々は「ウェアルフ」(アングロサクソン語で異邦人)と呼ばれ、これがウェールズの語源となったそうです。北部に追いやられた原住民にはスコット人が含まれ、後にスコットランドと呼ばれるようになります。こうした中で、原住民の間ではゲルマン系への抵抗の象徴として「アーサー王伝説」が生まれたとされています。このため、アーサー王伝説はケルト系の価値観に基づいた物語といえるのかもしれません。
最初の「イングランド王」であるアゼルスタンの時代に、「賢人会議(witenagemōt)」という議会の起源ともいえる機関が設置されました。以降、王たちは立法に深く関わるようになり、有力者との定期的な会議を行いました。征服王ウィリアム1世も賢人会議を尊重しました。
アンジュー帝国を築いたヘンリ2世の時代には議会が「パルルマン」と呼ばれ、これが後に「パーラメント」という用語になりました。エドワード証聖王を崇敬していたヘンリ3世の時代には、ウェストミンスター修道院の再建が進むとともに、ウェストミンスターが宮殿と政庁所在地を兼ねるようになりました。この頃には、騎士や都市市民も議会に出席するようになり、エドワード3世の治世からは貴族院と庶民院の2院制が取られるようになりました。
イングランドでは王位継承争いが頻繁に起こり、議会はその調整役を果たしていました。同時期のフランスでは王位継承争いがほとんど起きず、この違いが「議会」と「王権」の力関係に大きな影響を与えたと考えられます。
旅行中、ロンドン塔でテューダー朝の展示を観た際には、この本で得た知識が大いに役立ちました。下巻のステュアート朝に関する部分を読んでいれば、エディンバラ城やスコットランド国立博物館の展示をさらに楽しめたと思いますが、旅行までに読む時間が取れなかったのが残念です。
下巻では、清教徒革命(イングランド内戦)をはじめとする王権と議会の衝突が描かれます。オリバー・クロムウェルが軍を再編し「国王殺し(regicide)」を成し遂げたことで一時的に共和政となりますが、クロムウェルの死後、チャールズ2世による「王政復古(restoration)」が実現します。
その後、ハノーヴァー朝が始まり、トーリとホイッグという政党が生まれました。この時代には初代首相ウォルポールが登場し、彼の時代は「ウォルポール平和」と呼ばれます。ヴィクトリア女王の時代には繁栄が極まり、ロンドン塔で観た装飾品のきらびやかさが印象的でした。ヴィクトリア&アルバート博物館にも行きたかったのですが、時間の関係で断念しました。
イギリスは戦勝国ではありながら、第一次世界大戦と第二次世界大戦に参加し、大きなダメージを受けました。戦後、アトリー、サッチャー、ブレアという3大改革政党の時代を経て、スコットランドに権限が委譲され、スコットランド議会が設立されました。エディンバラのホリールード宮殿向かいにある特徴的な建物がその議会です。
イギリスには「BBC議会」というチャンネルがあり、貴族院と庶民院の審議を一日中放送しているそうです。「議会」が生活の一部であることがうかがえます。ウエストミンスターを見学できなかったのは残念ですが、またの機会に訪れたいと思います。
ところで、ところどころ出てくる用語に馴染みがあると感じたのは、中学生時代に触れたゼロ魔やギアスの影響かもしれません。思春期に出会ったものが記憶に強く残るのだと改めて実感しました。
麻雀1年目の教科書
友人と初めて麻雀をすることになり、初めて打った際に、人の助けがなければ上手く打てず購入した本です。それまで麻雀について何も知らなかったため、ここまで戦術的なゲームであることに驚きました。
中学生のアカギが、ルールを知らない状態から代打ちの矢木に勝ったのは、どう考えても常人離れした才能だと思います。私自身、牌効率を考えながら打つためのシンキングタイムがなかなか短くならず、辛さを感じていますが、それでもセオリーを頭に入れることができました。
また麻雀を打つ機会があれば、まずこの書籍を参考にすることになると思います。とても良い本でした。
地面師 他人の土地を売り飛ばす闇の詐欺集団
Netflixで『地面師』を一気に観た後、思わず手に取った本です。これはドラマの原作小説ではなく、参考文献となったノンフィクションです。
ドラマ(および原作小説?)では誇張されている部分が多いようですが、地面師たちの仕事には杜撰なプロセスも見受けられたとのことです。それでも人が騙されてしまうのは、確証バイアスやサンクコスト効果といった心理的な要因によるのでしょう。こうした警戒すべき存在をドラマという形で話題にしたことは、模倣犯を生むリスクもある一方で、騙されないための啓蒙的な役割も果たしたのではないかと思います。
積水ハウス事件で一番驚いたのは、社長派と会長派の対立が実際に存在しており、会長が責任を取るように求めた社長退任の要求が棄却され、結果的に落ち度のない会長が解任されたことです。この件はドラマでは描かれておらず、一層驚きを感じました。
また、なりすまし役が急に来られなくなり、手配師が急遽成り代わったというエピソードも実話だったことには驚きました。これは積水ハウス事件ではなく、新橋の白骨死体事件(ドラマ冒頭で描かれた事件に似ているもの)での出来事です。
『地面師』を観た後に土地購入の取引があったら、きっとこの知識を活かしつつ楽しむことができたのではないかと思います。その機会がなかったことが少し残念です。
お金のむこうに人がいる
本書を読んだきっかけは正直あまり覚えていませんが、読んで良かったと感じた一冊です。「僕らが紙幣を使っている理由はジャイアンリサイタルと同じである」といったユニークな表現が冒頭にあり、そこから自分のお金に対する凝り固まった価値観がほぐされていく感覚を覚えました。
「円の普及」が明治時代に急速に進んだ理由として、1873年の地租改正が挙げられます。この改正で「税の支払いを円貨幣でしか認めない」とされたためです。税金を納めなければ最悪の場合、10年以内の懲役となるため、円貨幣を手に入れる必要が生じたのです。
家の中に新しい貨幣を作ったらどうなるか、という例えはとても分かりやすいものでした。例えば、子どもたちに税金を払う義務を課し、払えなければスマートフォンを没収するというルールを設ける。子どもたちは家事をすることで貨幣を手に入れることができ、結果として「みんなのためにみんなが働く社会」が作り出されます。
本書では、社会全体にとって重要なのは、お金の移動(経済効果)ではなく、労働がモノに変換されることだと述べられています。「経済効果」という言葉に対して自分はポジティブな響きを感じていましたが、それが本質的な価値を表しているかどうかは中身次第であると気づかされました。
お金の移動ではなく効用に目を向けること、モノの価格の総額を表すGDPではなく生活の豊かさに目を向けること、そしてお金ではなくその向こう側にいる人に目を向けることを心がけたいと思います。
無(最高の状態)
科学的な論拠と仏典や古典からの引用が織り交ぜられて語られており、とても興味深い内容でした。
人間はポジティブな情報よりもネガティブな情報の影響を受けやすく、特にマイナスなことほど記憶に残りやすいそうです。この傾向は「ネガティビティバイアス」と呼ばれます。さらに、「ポジティブな情報は長持ちしない」という心理も備わっています。これは、人類が脅威に満ちた環境で生き抜くために臆病であることを余儀なくされた進化の結果といえるようです。
ネガティブな感情は現代においても必要であり、「敵ではなく、私たちを守ろうと気に病む乳母のような存在」とも言われています。この点では映画『インサイド・ヘッド』を思い出しました。
「一般の人と仏弟子の違いは〝二の矢〟が刺さるか否かだ」というブッダの言葉(雑阿含経)も印象に残りました。最初の悩みが別の悩み(二の矢)を呼び込み、同じ悩みが脳内で反復されることでダメージを受けてしまう。この二の矢を止められない問題は「自己」の困難に行き着きます。
自己とは単一の存在のように思えて、実際にはさまざまなツールが集まったパッケージのようなものだと本書は述べています。特に「物語」が脳内で自動的に動き出し、それを唯一の現実だと思い込むことに気づいていない点が問題だとされています。この問題を解決するためには、「セットとセッティング」という観点から、自己を捨てても恐怖を抱かないメンタルを整える必要があるとのことです。
また、内受容感覚を養うための「スダルシャンクリヤ」を試していましたが、骨折をきっかけに中断してしまっていました。本書を読んで、改めて再開してみようと思います。
以下のように丁寧語に統一し、誤字脱字を修正した文章をご確認ください。
他者と働く
こちらは別途ブログ記事を書きました。
漫才過剰考察
冒頭の「これまで」がとても印象的で気に入りました。M-1グランプリの解剖や寄席に関する考察も興味深く、(客観的なエビデンスの提示が欲しいと思う場面はあったものの)非常に面白い内容でした。
最初に試していたとされる新書のような書き味で読んでみたかった書籍です。中学校時代に一人称の二次創作SSをよく読んでいた私でも(?)、口語での記述にはやや読みづらさを感じました。
最高の老後
こちらは別途ブログ記事を書く予定です(と自分に発破をかける)。
年金不安の正体
PIVOTの動画を偶然観て、面白そうだったので購入した書籍です。年金制度について全く知らないまま社会保険料を納めてきたため、大変参考になりました。
年金制度が賦課方式であることは理解していましたが、「年金積立金の運用が好調」というニュースで混乱していました。実際には、現役世代が多かった時代に余剰となった資金を蓄えたものであり、これが積立金となっています。この仕組みは「修正積立方式」という紛らわしい名前が付けられており、名付けの重要性を改めて感じました。
2004年の年金制度改革で採用された「有限均衡方式」により、少子化の影響を緩和しつつ、2100年までに積立金を徐々に取り崩して均衡を目指すプランが導入されました。しかし、2022年には出生率が再び低下しており、楽観視は難しい状況です。また、「拠出の固定化」による年金原資の制約や所得代替率の設定が具体的に説明されており、理解が深まりました。
消費税やベーシックインカムに関連する議論も興味深く、非常に学びの多い一冊でした。
ホワイトカラー消滅
本書は、内容全般が非常に興味深く、多くを学ぶことができました。しかし、もやもやした点が2つあります。
1点目は参考文献へのリンクがないことです。冒頭で言及されている三菱総合研究所のレポート スキル可視化で開く 日本の労働市場 など、リンクがあればより良かったと感じました。
2点目は「ホワイトカラー」が指す範囲が曖昧であることです。Wikipediaによると、ホワイトカラーとは「知的労働や事務系、営業・販売系職など」に就く人々を指します。本書では、AI革命によりローワーホワイトカラーが淘汰され、アッパーホワイトカラーだけが残るとされており、それを前提に議論が進んでいます。しかしながら、一部ではホワイトカラーの定義が狭く感じられる記述もあり、この曖昧さが気になりました。例えば、書籍の中で逃げ恥の平匡さんはホワイトカラーではないと述べています。どうやら終身年功制でなければ、ここでの「ホワイトカラー」の対象ではないと言及されています。更に、冒頭では三菱総合研究所のレポートを引用して「ホワイトカラー(事務担当)は2035年に180万人の余剰になる」と言っている。おそらくこのレポートは労働政策研究・研修機構の統計を参考にしていると思われますが、更に、冒頭では三菱総合研究所のレポートを引用して「ホワイトカラー(事務担当)は2035年に180万人の余剰になる」と言っている。おそらくこのレポートは労働政策研究・研修機構の統計を参考にしていると思われる。労働力調査で用いている職業分類 を見ると、ここでの事務従事者はホワイトカラーのサブセットの一つであるように思えました。
とはいえ、1ソフトウェアエンジニアとして、これまで行ってきた業務の一部が生成AIに代替される未来は容易に想像できます(実際にその兆候はすでに見られます)。自分も「漫然とホワイトカラー」の一員ではないかという意識を持ちながら読み進めました。
今迎えているインフレモードと労働供給制約社会の組み合わせという悪くはない状況の中で、人員が余剰になる日本のグローバル産業はどのように外貨を稼いでいくべきか、そしてローカル経済でのエッセンシャルワーカーの不足を各セクターでどのように解決していくべきか、個人個人のスキリングどれも興味深く読むことが出来ました。最後に、それらをベースにした20の提言というのがあり、それも本書をそれまで読んできているととても納得感のあるものでした。
本書は、自分のキャリアをどうすべきか深く考えさせられる一冊でもありました。
エレガントパズル
こちらは別途ブログ記事を書く予定です(と自分に発破をかける)。
プロダクトマネージャーのしごと 第2版
こちらも別途ブログ記事を書く予定です(と自分に発破をかける)。
「他者と働く」を読んだ
概評
約2年前、僕の上司が「Team Topologies」「組織デザイン」「他者と働く」の3冊を「3大おすすめ書籍」として挙げていました。「他者と働く」は以前から読もうと思っていたものの、内容をよく知らなかったため、必要なタイミングで読むことができず、放置してしまっていました。
SREという横断的な組織に属している特性上、異なるナラティヴを持つ人たちと一緒に仕事を進めることが多いと感じています。さらに、約1年前にマネージャになってからは、その傾向がより顕著になりました。特に、この本で言及されている「私とそれ」の関係に近い状況がほとんどでした。そのままではうまくいかず、偶然「私とあなた」の関係に変わったことで改善したケースもあれば、依然としてうまくいかないままのケースも多く残っているように感じます。
本書を読み終えた感想としては、日々の仕事の中で自分が抱えていたモヤモヤに対して指針を示してくれる内容だったのではないかと思います。ただし、個人的には「解釈」が非常に難しいテーマだと感じました。「観察」が中途半端になると、「解釈」も当然中途半端になり、その結果、効果のない技術的アプローチを取って挫折する、という状況が目に浮かびます。本書で指摘されているように、「解釈にはパートナーが重要」とのことで、そういったパートナーを見つけることが、自分にとっての課題になるのかもしれません。
印象的だった内容
適応課題を解決するのが「対話」
ハイライト
適応課題(adaptive challenge)とは、既存の方法では一方的に解決できない、複雑で困難な問題を指します1。一方で、既存の方法で解決可能な問題は技術的問題(technical problem)と分類されます。
適応課題に対しては、対話(dialog)を用いたアプローチが有効です。対話とは、一言で言えば「新しい関係性を構築すること」2。権限や立場に関係なく、自分の中に相手を見出し、相手の中に自分を見出すことで、双方向にお互いを受け入れていく過程を指します。
哲学者マルティン・ブーバーは、人間同士の関係性を「私とそれ」という道具的な関係と、「私とあなた」という固有の関係性に分類しました。「私とそれ」の関係性は必ずしも悪いものではなく、効率性を重視した関係を築くことで、円滑な業務や組織運営が可能となります。
本書では、「私とそれ」の関係性の例として、レストランのウェイターが挙げられています。「店員」という役割を持つ相手には、水や料理を提供してくれることを期待します。この場合、相手の年齢や性別は問わず、道具的な応答が求められます。
しかし、「私とそれ」の関係性の中で適応課題が生じた場合、関係性を「私とあなた」へと移行させる必要があります。その第一歩は、「こちら側」のナラティヴ(narrative)の変化です。
ナラティヴとは、物語を生み出す「解釈の枠組み」を指します。この枠組みは、立場や役割、専門性などによって形作られます。例えば、「上司とはこうあるべき」「部下とはこう振る舞うべき」といった暗黙の解釈が挙げられます。一方的なナラティヴに基づいて相手を見ると、相手が誤っているように思えることがあります。しかし、それは相手側のナラティヴから見た場合にも同様です。
対話とは、このような「ナラティヴの溝に橋を架ける」行為であると言えるでしょう。
所感
この「私とそれ」と「私とあなた」の関係性を、無理やり Team Topologies 3 における概念で解釈すると、interaction modes の X-as-a-Service と Collaboration の一部として捉えることもできるかもしれません。X-as-a-Service モデルがうまく機能するのは、「サービス境界が正しく選択され、適切に実装され、さらにサービスを提供するチームが優れたサービスマネジメントを実践している場合のみ」とされています。しかし、例えば環境の変化などによってこのモデルが機能しなくなると、組織課題に発展する可能性があります。そのような状況下では、Collaboration を通じてナラティヴの溝に橋を架けていくアプローチが有効ではないかと感じました。
また、この「ナラティヴの溝に橋を架ける」という作業は、メアリー・フォレットが対立解決の方法として提唱した 統合(Integration) にも通じるものがあるように思います。私は社内研修を通じてこの統合の概念を学びましたが、それは抑圧(domination)や妥協(compromise)のように一方が犠牲を払う解決策ではなく、対話を通じて対立を乗り越え、お互いの利益を最大化する方法です。
複数の書籍や論文で似たような事象が言及されているのは、それぞれが適応課題に直面し、それを解決するために異なる形で整理・言語化を行った結果であり、これが普遍的な解決策として共有されていることの証と言えるのではないでしょうか。
特に「私とそれ」という関係性は、複数の部門や組織をまたがる横断組織においてよく見られるように感じます。本書で述べられている通り、その関係が機能している間は問題ありませんが、機能しなくなる場面も少なくないでしょう。たとえば、従来のDevとOpsの関係性がその一例です。そして、DevOps という概念は、もしかしたらナラティヴの溝に橋を架けるアプローチを具現化した一つの形なのかもしれません。
適応課題の4タイプ
ハイライト
これら4つのタイプに共通するのは、いずれも既存の技法や個人のスキルだけでは解決できない問題であることです。さらに言えば、人と人、組織と組織の「関係性」の中で発生する問題だという点です。
1つ目の「ギャップ型」は、大切にしている「価値観」と実際の「行動」にギャップが生じるケースです。この場合、問題は(狭い意味で)合理的に発生します。そのため、この合理性の根拠を変えるように働きかけることが求められます。
2つ目の「対立型」は、互いの「コミットメント」が衝突するケースです。
3つ目の「抑圧型」は、「言いにくいことを言わない」状態です。関係性が原因で発言しづらかったり、発言するとトラブルや損失を被るリスクがある場合に発生します。たとえば、既存事業の将来性が乏しいとわかっていても撤退できない状況がこれに当てはまります。
4つ目の「回避型」は、痛みや恐れを伴う本質的な問題を避けるため、逃げたり別の行動にすり替えたりするケースです。
所感
例えば、開発組織では、これらのタイプの適応課題がどのような形で現れるかを考えてみました。
ギャップ型
技術的負債への向き合い方が例として挙げられるかと思います。多くのソフトウェアエンジニアは、将来的な開発速度や開発体験、プロダクト品質の悪化を防ぐため、技術的負債の解消を重視し、品質の高いコードベースを維持したいと考えます。一方で、顧客にできるだけ早く機能を届けることは、ビジネスの短期的な目標から見れば非常に合理的です。顧客に早く価値を届けることで評価を得て、売上を伸ばし、投資の原資を作ることも重要な目標です。このように、価値観と行動にギャップが生じる場面があるはずです。
対立型
開発組織とセキュリティ組織のコミットメントの違いが典型例です。開発チームは新機能を迅速に導入したいと考える一方、セキュリティチームはリスクを避けるために厳しいチェックプロセスを設けることがあります。例えば、開発チームが納期内のリリースを目指している一方で、セキュリティチームがセキュリティインシデントの防止を優先している場合、これらの目標の違いが対立を生む可能性がありそうです。
抑圧型
問題を指摘した人やチームが「解決の責任」を押し付けられる雰囲気があると、重要な課題が表面化しない可能性がありそうです。現在、私が所属している開発組織では横断組織が存在し、個人が挙げた課題に対して組織として動く仕組みがあるため、この種の問題が起きにくい構造を作れていると感じます。このような仕組みは、抑圧型の課題を防ぐ上で非常に有効であるように感じます。
回避型
本質的な課題を避け、短期的な解決策に頼る例が挙げられます。たとえば、設計の見直しという本質的な問題を回避し、インフラのスケールアップで対応してしまう状況です。また、サーベイ結果を受けて、本質的な課題やユーザーの真のニーズを深掘りするプロセスを回避し、表面的なHow(解決方法)に飛びついてしまうことも、この型に当てはまるように思います。
溝に橋を架けるステップ
ハイライト
- 準備:「溝に気づく」
- 観察:「溝の向こうを眺める」
- 相手の立場や状況を深く理解するための情報収集を行います。
- 相手にどんなプレッシャーがあるのか。
- 相手の責任や仕事上の関心は何か。それらが生じた背景は何か。
- 具体的には、以下のような行動を取りうると思います。
- フラットに意見交換できる人に聞いてみる。
- 数値的データを収集する。
- 部長や役員クラスの話を聞き、方針を探る。
- 自分が安全な場所にいながら相手にリスクを負わせる関係性があった可能性にも気づけます。
- 相手の立場や状況を深く理解するための情報収集を行います。
- 解釈:「溝を渡り橋を設計する」
- 観察で分かってきたことを眺めて、そこから相手のナラティブを自分なりに構成してみます。
- 相手のナラティブの中に立ってみて自分を眺めると、どう見えるのかを知ります。
- ナラティブの溝に架橋できるポイントを協力者などのリソースを交えて考えます。
- 介入:「溝に橋を架ける」
- 解釈の段階にはいって、橋の設計をし、介入する段階で初めて技術的解決が機能するようになります。
- また、この介入が次の観察への入り口となる循環的なプロセスでもあります。
所感
職種が異なる場合、その職種が大切にしている価値観や文化を知ることは有意義だと思います。ソフトウェアエンジニアの間で重視される価値観や文化には、一般的に共有されるものがいくつかあるように感じます。同様に、他の職種にもそれぞれ固有の価値観や文化が存在するのではないでしょうか。
また、この本の後半で言及されていた「ナラティブに招き入れる」という考えに関連して、「ナラティブに踏み入れる」という視点も有効かもしれません。具体的には、相手のナラティブの中に入り込み、そこから自分のナラティブを眺めるということです。
ちなみに、この本を読むまで「多能工化」というトヨタ生産方式の概念を知りませんでしたが、とても興味深いと感じました。特に、「自分よりも後工程を担当すれば、自分の工程で行ったことが後工程にどのような影響を与えるかを知ることができる」というフレーズが印象に残りました。今後どこかのタイミングで、このテーマについて詳しく読んでみたいと思います。
左腕を骨折した
※ o-1 preview にエッセイ風にしてもらった。凄い。
うっかり階段で足を滑らせた。それだけだ。咄嗟に左腕で体を庇おうとしたのか、左腕を強く打ちつけながら階段を転げ落ちた。
同時に右手の皮が剥けており、その出血の方が気になって、当初は左腕の痛みにあまり注意を払っていなかった。最初は打撲程度のじんじんとした痛みだったが、動かすときの痛みがやけに激しいと感じていた。
帰宅して左手と右手をよく見比べてみると、左手の血色が随分と悪い。それに、腕を曲げたり捻ったりするたびに痛みが増している。指を動かすだけでも痛みが走る。
「さすがに骨折ではないと思うけれど、相当打ちどころが悪かったのだろうか」
そう自分に言い聞かせながらも、不安が募る。痛みはどんどん増していき、ベッドに入る頃には寝付くのが難しいほどだった。やっとの思いで眠りについたが、4時間ほどで痛みで目が覚めてしまった。その時の痛みはこれまでで一番強かった。
耐えかねて、ロキソニンを飲み、効果が出るまでNetflixで「イエスタデイ」という映画を観ることにした。予告があまりに良かったせいか、期待が高まりすぎてしまったが、映画に集中できたおかげで痛みを一時的に忘れることができた。2時間後には薬が効いて楽になり、再び眠りにつくことができた。
翌朝、早速病院に向かった。整形外科と内科を兼ねているその病院は非常に混雑しており、待合室は満員だった。待ち時間の2時間のほとんどを立って過ごした。
診療時間が過ぎて30分ほど経った頃、ようやく名前が呼ばれた。医師は疲労の色を隠せない様子だったが、丁寧に対応してくれた。レントゲンを撮ることになり、さまざまな角度から撮影するために腕を捻る必要があった。その度に痛みで思わず息が漏れる。「ごめんね」と医師に気遣われ、申し訳ない気持ちになった。
「骨折ですね」
医師は上腕骨の肘に近い部分を指しながらそう告げた。素人の私にはレントゲン写真からは分からなかったが、確かに骨が折れているという。待合室で待つ人々の姿が頭をよぎり、それ以上詳しく尋ねることはできなかった。
幸い、手術は必要なく、すぐに固定することになった。以前、右手の小指を骨折したときは石膏のギプスだったが、今回は樹脂製のものだった。硬化するときに温かくなる感覚が新鮮だった。
固定されると不思議と痛みは和らいだ。もちろん動かせば痛むが、安静にしていれば耐えられる程度だ。病院に行く前は、まさか固定されるとは思っていなかったので、これからの日常をどう過ごすか思いを巡らせながら帰路についた。
まず仕事について考えた。タイピングは仕事上必須だが、固定されているのは上腕から手首まで。指は動くものの、動かすと少し痛みが走る。ギプスのせいで手全体が浮いてしまい、いつものポジションでタイピングするのは難しい。これでは仕事のパフォーマンスは大幅に低下してしまう。年末にまとめて休む予定だった休暇を前倒しで取得することに決めた。その日どうしても必要な対応は、片手で何とかこなした。
次に家事はどうだろう。強く握ると痛みが走り、ほぼ握力はゼロと考えていい。可動域も狭く、できることは限られてくる。包丁は使えないし、服を畳むことも難しい(ぎりぎりハンガーにかけることはできる)。新品のペットボトルは開けられず、雨の日の買い物も困難だ。できなくはないが、質や速度が著しく落ちる。厳しい現実だ。
時間ができたので、「Atsueigo」の発音マスタークラスをすべて視聴することができた。視聴しながらメモを取るのだが、スマホでの入力はやや手間だ。残りの時間は本でも読んで過ごそうかと思う。
幸いにも、回復の兆しは見えている。来週再び病院に行く頃には、タイピングもできるようになっているかもしれない。元通りにタイピングできるかどうかは、ギプスが外れるかにかかっている。ビタミンDとKのサプリメントを摂り、牛乳でカルシウムを補給して、骨の修復を促している。早く治ってほしいものだ。
Karpenter v1.0 で Expiration が Graceful から Forceful になった
3行で
- Karpenter v1 では expiration の方式が Forceful に変更され、drifted や consolidation と同様の PDB や do-not-disrupt の考慮がなくなりました
- これにより、クラスタ管理者はノードを一定期間で強制的に削除できるようになり、高いセキュリティを維持しやすくなりました
- この変更を踏まえ、
expireAfterの設定を再検討することが重要そうです
そもそも Karpenter の Expiration とは
Karpenter の expiration は、alpha 版の Provisoner リソースで導入された spec.ttlSecondsUntilExpired から始まった機能です 。
その後、beta 版で NodePool リソースの spec.disruption.expireAfter に名称変更され1、GA では階層が変わり spec.disruption.template.spec.expireAfter となりました 2。
名称や階層の変更はあったものの、機能の本質は「ノードの最大稼働時間を設定し、それを超えたノードを削除する」という点で一貫しています。この仕組みにより、長期間稼働するノードを適切にリフレッシュし、セキュリティリスクを軽減することが目的とされています。
初期の alpha 版では consolidation 機能がまだ存在せず、ttlSecondsUntilExpired の設定がリソース効率化やコスト削減にも活用されていました。また、当時は drift 検知やノード更新の仕組みがなかったため、expiration のセキュリティ的な意義がより強かったと記憶しています。
v0.37 以前の Graceful Expiration
Karpenter は karpenter #59 から v0.37 まで Graceful Expiration を採用していました。この名称は、v1 で採用された Forceful Expiration と区別するため、便宜的に使われています 3 。
以下の図は forceful-expiration の design doc からの引用です。図の中に Expired というラベルの付いた矢印があり、State1 (Running) から State2 (Disruption Candidate) に遷移することが示されています。これは Drift や Consolidation のノード termination と同様の処理フローです。

State2 (Disruption Candidate) に遷移する際、以下の条件がチェックされます(pkg/controllers/disruption/controller.go#L147-L150, pkg/controllers/disruption/types.go#L63-L144):
- NDB (Node Disruption Budget) が許容されているか
- ノードや pod に do-not-disrupt の annotation が付いていないか
- PDB によるブロックが行われていないか
Graceful Expiration の利点は、ノードが expiration に達しても pod を安全に退去させることができる点です。一方、セキュリティ面では、EKS AMI が drift している場合などに対応が滞る可能性がありました。一定のセキュリティ要件が求められる環境では、この挙動が課題となることがあったと思います。
v1 以降の Forceful Expiration
以下の図は、v1 以降における expiration を含むノード termination フローを示したものです。こちらも forceful-expiration の design doc から引用しています。
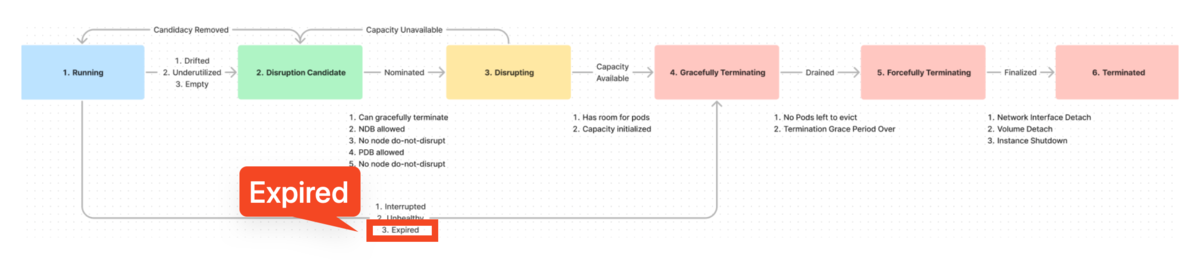
図を見ると、Expired の位置が State1 (Running) から State4 (Gracefully Terminating) に移動していることが分かります。この変更により、v1 では Interrupted や Unhealthy と同様のハンドリングが行われるようになりました。
具体的なコード変更 4 について、v0.37.6 と v1.0.5 の流れを比較します:
v0.37.6
- NodeClaim が expired になっている場合は、NodeClaim に
ExpiredというConditionが設定されます (pkg/controllers/nodeclaim/disruption/expiration.go#L62) Expiredというconditionがある場合に、shouldDisrupt()という関数がtrueで返りdisruptionの候補ノードとなります (pkg/controllers/disruption/controller.go#L147)- この候補ノードのリストアップの処理は、例えば
DriftedやEmptyといった各メソッド(pkg/controllers/disruption/controller.go#L77-L90) ごとに行われます - 先ほど言及したように、この候補ノードを決めるときに「PDBによるblockingがされていないか」などのチェックが走ります
- この候補ノードのリストアップの処理は、例えば
- 他のmethodとも共通しているDisruptの処理に進みます(pkg/controllers/disruption/controller.go#L174-L177)
- Replacementのnodeを作ったりもする (pkg/controllers/disruption/controller.go#L200-L206, pkg/controllers/disruption/expiration.go#L116-L119)
v1.0.5
- NodeClaim が expired になっている場合は、NodeClaimを削除する (pkg/controllers/nodeclaim/expiration/controller.go#L60-L63)
この変更により、v1 の Forceful Expiration ではセキュリティ要件を満たしやすくなる一方で、pod の安全な退去が保証されないリスクが生じます。
まとめ
Karpenter v1 で Expiration の挙動が変わったことを踏まえ、expireAfter パラメータの再検討が推奨されると思います。たとえば:
expireAfter: neverに設定すると、中断を防げますが、EKS の AMI 更新に伴う drift の解消ができなくなります。- 一方で、
expireAfterを極端に短くすると、頻繁な pod 中断やノードの無駄な削除/起動が発生する可能性があります。
それぞれの環境に求められる要件をベースに適切な値を設定することが重要そうです。
- https://karpenter.sh/v0.32/upgrading/v1beta1-migration/#ttlsecondsuntilexpired↩
- https://karpenter.sh/v1.0/upgrading/v1-migration/↩
- karpenter/designs/forceful-expiration.md at main · kubernetes-sigs/karpenter · GitHub↩
- BREAKING: revert back to forceful expiration by default #1333↩
- https://github.com/kubernetes-sigs/karpenter/blob/main/designs/nodeclaim-termination-grace-period.md↩
家建てて引っ越してから半年経ったのでふりかえる
3月下旬に注文住宅が完成し、ちょうど1ヶ月後の4月下旬に新居に引っ越したので、住み始めてから半年が経ちました。ここで一度振り返ってみるのも面白いかと思い、書いてみます。
なぜ注文住宅を選んだか
住宅の購入を考え始めたのは、僕とパートナーの両方が周囲の人たちから住宅購入の話を聞いたことがきっかけでした。
住んでいた賃貸に大きな不満はなかったものの、長く住もうとは思えなかったこともあり、住宅購入を検討し始めました。住宅価格が上がっていることも知っていたため、焦りもあったのかもしれません。
最初から注文住宅に決めていたわけではなく、注文住宅・建売・マンション・買わずに賃貸 という選択肢をフラットに見ていこうと思っていました。しかし、実際にはマンション購入には少しネガティブな印象を持っていました。理由の一つは価格の上昇率が高すぎること。購入が投資目的でなければメリットが少ないと感じたからです。また、建物のメンテナンスに関して住人同士で合意を取る必要がある点も難しさを感じました。
まず、あまり深く考えずに注文住宅のモデルハウスを見に行きました。ただ、これは意思決定をする上で良いプロセスではなかったかもしれません。
後から僕は「注文住宅の方がリードタイムが長いので先に見に行った」などと友人に説明しましたが、実際のところ何も考えずに行動していたのです。
注文住宅はあまりにも魅力的で、その魅力を語る営業さんたちのアピールも実に巧みでした。気がつけば「家とは多くのお金をかける価値があるものだ。仕方ないのだ」と思い、注文住宅を買うことが自分たちにとって最適解である理由を探し始めていました。典型的な確証バイアスです。
結局、建売についてはあまりリサーチをしないまま注文住宅で進めることを選びました。現時点では、その決定に後悔はありません。
どのようにハウスメーカーを選んだか
まず、家に求める機能要件と非機能要件の中で重視したいものについて、パートナーと合意を取りました。耐震性や断熱性、デザインなど、どのくらいが望ましいかを決めました。例えば、耐震性に関しては「許容応力度計算による構造計算で耐震等級3を必須とする」といった内容です。
これらの観点やその度合を洗い出すために、インプットが足りないと感じたため、『エコハウス超入門』を読んでハウスメーカー選択の観点に漏れがないようにしました。「どのくらいの断熱性が必要か?」「空調はどうあるべきか?」といった観点で、この本が非常に参考になりました。
その後、各ハウスメーカーの特徴を、営業さんからの説明や比較書籍を参考に整理し、合意した住宅要件に合致するかを確認しました。デザインに関しては判断が難しかったため、なるべく30坪程度のモデルハウスを見に行って確認しました。住宅展示場のモデルハウスは広すぎて参考にならなかったのが正直なところです。
コストも重要な要素の一つです。2社に絞った段階で詳細な見積もりをもらい、精緻なコスト比較を行いました。その際、FPの方にシミュレーションをしていただき、許容可能な額を明確にしました。これがなければ、少しでも安い方に傾いてしまったかもしれません。
ゆっくりとこの作業を進めたかったのですが、割の良い期間限定キャンペーンを目の前にぶら下げられ、想定よりも急いで決める必要がありました。
どのように土地を選んだか
ハウスメーカーの時と同様に、土地を選ぶ際の観点を洗い出し、パートナーと僕それぞれで優先度を付けて合算しました。
FPの方によるシミュレーションと建物のコストが明らかになったことで、土地にかけられる予算が決まりました。その上で「駅からの距離」「2階建てか3階建てか」「理想とする建ぺい率」「実家との距離」「最寄駅からの通勤利便性」などの条件を出すと、おおよその新居の最寄駅の候補が絞られました。
これらの条件を伝え、ハウスメーカーの営業さんに土地を探してもらいました。もちろん、自分でもSuumoで調べたりもしました。
家を建てる際の補助金や子育て支援の手厚さを考えると、23区外であっても東京都に住むメリットは大きいと感じていたため、東京都内という条件も加わっていたかもしれません。
最終的には、営業さんにいくつかの土地を案内していただき、その土地に建てることを仮定したラフな設計図をもらって決めました。
その地域の将来性について緻密にリサーチすべきだったのでしょうが、道路計画を確認する程度にとどまっていました。住んでから、予想外のポジティブな要素が見つかりホッとした記憶があります。
ちなみに、土地売買に関しては『地面師たち』を見た後であれば、もっとエキサイティングに取引に臨めたでしょう。
設計はどのように進んだか
土地の測量が終わった後、設計士さんがアサインされ、1〜2週間に1回のペースで打ち合わせをすることになりました。
所感としては究極のウォーターフォール開発のようで、こちらの要求をいかに整理して早めに伝えるかが鍵でした。各段階の設計を決める前に、その前のフェーズが固まっていないと進められません。例えば家の形が決まらなければ間取りは決められず、間取りが決まらなければ照明も決められないといった具合です。
要件を明確にするため、何らかのフォーマットを用意して書き出せばよかったのですが、当時はそれが頭になく、箇条書きで列挙したmust-haveとnice-to-haveをお渡ししました。今思えば、howではなくwhatとwhyを書き、howは設計士さんに考えてもらうのが良かったかもしれません。
『ぜんぶ絵でわかる1木造住宅』を読んで勉強してみたものの、やはり素人には限界があり、設計段階では設計士さんとのやり取りに苦労しました。しかし、営業さんが非常にバランス感覚に優れていて手厚くサポートしてくれたおかげで、当初より設計が大きく改善されました。運が良かったと思います。
ハウスメーカーを決めてから3〜4ヶ月かけて設計やインテリアの打ち合わせを行い、工期自体はおおよそ5ヶ月ほどかかりました。
設計でこだわったポイント
まずは全館空調です。断熱・気密性能が高ければ、第一種換気の給気を温めたり冷やしたりするだけで十分であると『エコハウス超入門』にも記載があります。ダクトなどの設備が必要なため初期費用がかさみ、天井高にも制限が設けられますが、長期的に見れば全室エアコンよりも安価で快適ではないかと考えました。夏や梅雨の時期に通風に頼るのは気温的に難しく、カビやダニとの共存を避けられません。第一種換気と冷房の連続運転は健康面でもプラスだと考えました。
リモートワークのためのスペースを2つ作ったので、そもそも全室エアコン設置は現実的ではなかったように思います。
次に階段の幅です。以前住んでいた賃貸がメゾネットタイプだったため、冷蔵庫や家具の搬入で苦労しました。建築基準法で手すりの設置が義務付けられているため、搬入可能なサイズは階段の幅よりも狭くなります。「大は小を兼ねる」と勢いで買った4〜5人用の冷蔵庫は、玄関まで来て引き返していったことがありました。この苦い経験から階段幅を広めにし、結果的に開放感もあり業者の方からも運びやすいと言われました。
2階リビングもこだわりポイントです。昼間に人目を気にせずカーテンを開けられ、かなり明るいです。Low-E複層ガラスを利用しているため、昼は太陽光が反射して中が見えづらく、屋根の形に沿った天井を作れたことで空間の広がりも感じられます。
メンテナンス費用の抑制も考慮しました。衣類ガス乾燥機、浴室乾燥機、1階の掃き出し窓近くのスペースを設けて、ベランダを作らないようにしました。万が一衣類ガス乾燥機が動かなくなっても対応できます。ベランダは防水工事や屋根、手すりの修繕でコストがかかるためです。外壁はサイディングではなく、メンテナンス性に優れた吹付けとタイルを採用しました(ここは調査不足だったかもしれません)。
その他にも、採光やキッチン、洗面脱衣周りにこだわりを反映させています。
住み始めて半年経った感想
設計でこだわったポイントについては、ほとんど全てがうまく機能していると感じます。広いキッチンは思いがけず僕の自炊意欲を高めてくれたのは予想外の副産物でした。
土地選びについても、中型分譲地ということもあり、同じように注文住宅を建てた同年代の方々が住み始めていて、近隣トラブルも今のところありません。
一方、設計面で後悔している点もあります。
一つは、洗面所にドアをつけなかったことです。脱衣所と洗面所が分かれているため、脱衣所にだけドアをつけましたが、朝の支度をする時間が異なる場合、ドライヤーの音が寝ている人に聞こえてしまいます。ドアをつけない選択にも理由がありましたが、このデメリットは事前に認識すべきでした。
二つ目は、寝室のスペースを狭くしすぎたことです。寝るだけのスペースと割り切って小さくした結果、クローゼットとベッドの距離が近すぎて服を選びにくくなりました。賃貸時代がウォークインクローゼットだったので、ここは痛いデグレードでした。
むすび
様々なトレードオフを迫られるので、実際に使った時間以上にハードだったという感想です。そもそも「住宅購入をする」という選択が今のタイミングで良かったのかも分からず、不安は残っています。
設計段階で強く感じたことがあります。それは「ハウスメーカーでの建築において営業さんがとても重要ではないか」ということです。家を建てている複数の知人の話を聞いても同じことを感じます。人生で何度も家を建てるのは難しく、営業さんの顧客目線でのサポートに頼らざるを得ない場面があると思います。
ちなみに、家を建てる過程で最も驚いたのは地鎮祭です。ほぼ同時期に家を建てた先輩と地鎮祭の写真を見せ合ったときのことです。先輩の家と僕の家はかなり離れているにもかかわらず、同じ神主だったのです。その時は腹を抱えて笑いました。地鎮祭専門の神主がいるのでしょうか。てっきり地元の人が儀式をしているのだと思っていたので、本当に驚いた出来事でした。